版本 1.3.0¶
我们很高兴地宣布 AutoGluon 1.3.0 版本发布!
AutoGluon 1.3 主要关注稳定性和可用性改进、错误修复以及依赖项升级。
此版本包含 来自 20 位贡献者的 142 次提交!在此处查看完整的提交更改日志:https://github.com/autogluon/autogluon/compare/v1.2.0…v1.3.0
加入社区:

不支持加载使用旧版本 AutoGluon 训练的模型。请使用 AutoGluon 1.3 重新训练模型。
亮点¶
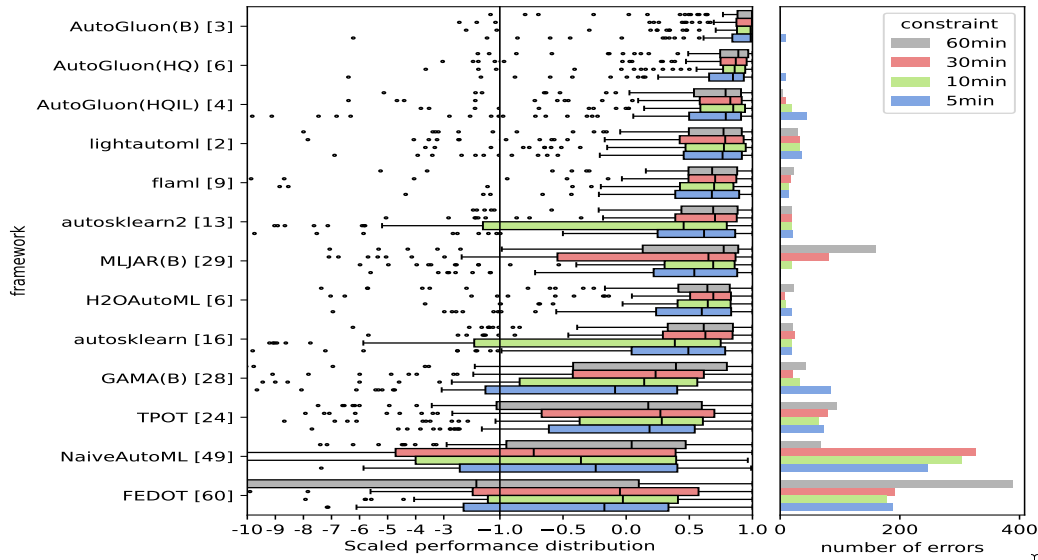
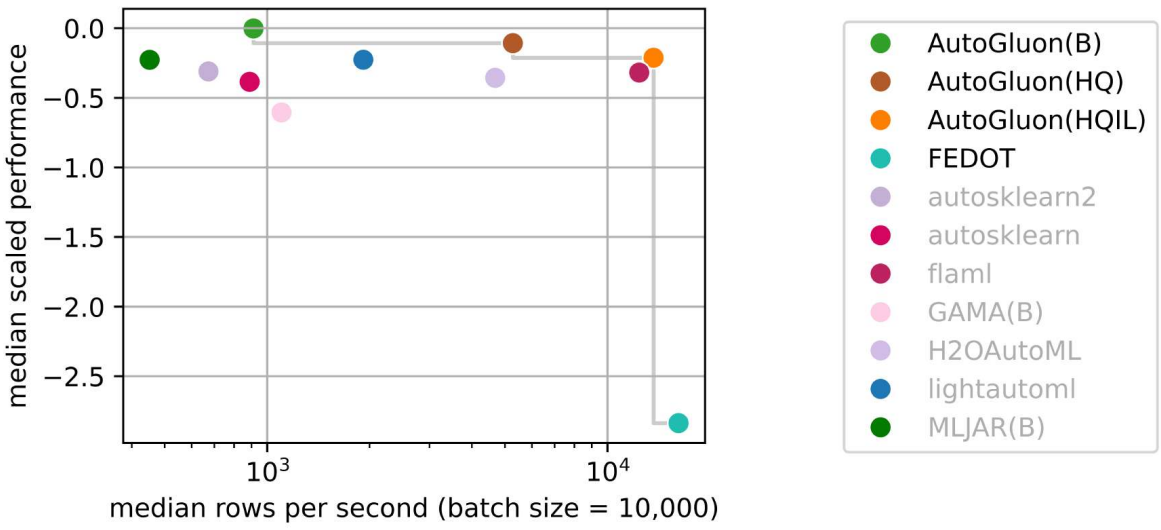
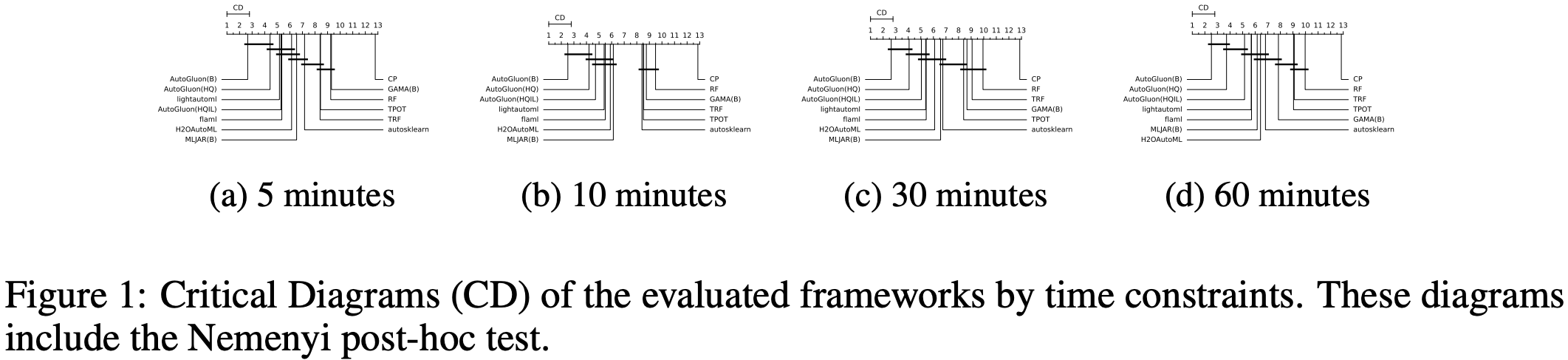
AutoGluon-Tabular 在 AutoML Benchmark 2025 中处于最先进水平!¶
AutoML Benchmark 2025 是一项对表格 AutoML 框架进行的独立大规模评估,展示了 AutoGluon 1.2 作为最先进的 AutoML 框架!亮点包括
AutoGluon 的排名在所有时间限制下通过 Nemenyi 后续检验,统计学上显著优于所有 AutoML 系统。
AutoGluon 在 5 分钟训练预算下表现优于所有其他 AutoML 系统在 1 小时训练预算下的表现。
AutoGluon 在所有评估的预设和时间限制下,质量和速度都达到帕累托效率。
带有
presets="high", infer_limit=0.0001(图中 HQIL) 的 AutoGluon 实现了每秒 >10,000 个样本的推理吞吐量,同时优于所有其他方法。AutoGluon 是最稳定的 AutoML 系统。对于“best”和“high”预设,AutoGluon 在所有 >5 分钟的时间预算下都没有失败。
AutoGluon 多模态的“技巧集合”更新¶
我们很高兴地宣布 AutoGluon 多模态 (AutoMM) 集成了一项全面的“技巧集合”更新。这项重要增强显著提高了处理图像、文本和表格数据组合时的多模态 AutoML 性能。该更新实现了各种策略,包括多模态模型融合技术、多模态数据增强、跨模态对齐、表格数据序列化、更好地处理缺失模态,以及一个整合这些技术的集成学习器以实现最佳性能。
用户现在可以通过初始化 MultiModalPredictor 时设置一个简单参数来访问这些功能,具体请遵循此处的说明下载检查点。
from autogluon.multimodal import MultiModalPredictor
predictor = MultiModalPredictor(label="label", use_ensemble=True)
predictor.fit(train_data=train_data)
我们感谢 @zhiqiangdon 做出这一重大贡献,增强了 AutoGluon 处理复杂多模态数据集的能力。此处是描述技术细节的相应研究论文:Bag of Tricks for Multimodal AutoML with Image, Text, and Tabular Data。
弃用和重大变更¶
以下已弃用的 TabularPredictor 方法已在 1.3.0 版本中移除(在 1.0.0 中弃用,在 1.2.0 中引发警告,在 1.3.0 中移除)。请使用新名称
persist_models->persist,unpersist_models->unpersist,get_model_names->model_names,get_model_best->model_best,get_pred_from_proba->predict_from_proba,get_model_full_dict->model_refit_map,get_oof_pred_proba->predict_proba_oof,get_oof_pred->predict_oof,get_size_disk_per_file->disk_usage_per_file,get_size_disk->disk_usage,get_model_names_persisted->model_names(persisted=True)
以下逻辑从 1.3.0 版本开始已弃用,并将记录 FutureWarning。功能将在未来版本中更改
通用¶
改进¶
(重要) 对
AbstractTrainer类进行内部重构,以提高可扩展性并减少代码重复。 @canerturkmen (#4804, #4820, #4851)
依赖项¶
将 numpy 更新到
>=1.25.0,<2.3.0。 @tonyhoo, @Innixma, @suzhoum (#5020, #5056, #5072)将 scikit-learn 更新到
>=1.4.0,<1.7.0。 @tonyhoo, @Innixma (#5029, #5045)将 ray 更新到
>=2.10.0,<2.45。 @suzhoum, @celestinoxp, @tonyhoo (#4714, #4887, #5020)将 torch 更新到
>=2.2,<2.7。 @FireballDWF (#5000)将 lightning 更新到
>=2.2,<2.7。 @FireballDWF (#5000)将 torchmetrics 更新到
>=1.2.0,<1.8。 @zkalson, @tonyhoo (#4720, #5020)将 torchvision 更新到
>=0.16.0,<0.22.0。 @FireballDWF (#5000)将 accelerate 更新到
>=0.34.0,<2.0。 @FireballDWF (#5000)将 pytorch-metric-learning 更新到
>=1.3.0,<2.9。 @tonyhoo (#5020)
文档¶
更新 CONTRIBUTING.md 中文档化的 python 版本。 @celestinoxp (#4796)
修复各种拼写错误。 @celestinoxp (#4819)
修复和改进¶
修复使用
uv在 colab 中安装 AutoGluon 源代码的问题。 @tonyhoo (#4943, #4964)确保当
path_suffix != None且path=None时,setup_outputdir始终创建一个新目录。 @Innixma (#4903)在调用
cuda.device_count()之前检查cuda.is_available(),以避免警告。 @Innixma (#4902)修复
get_approximate_df_mem_usage中罕见的 ZeroDivisionError 边缘情况。 @shchur (#5083)细微的修复和改进。 @suzhoum @Innixma @canerturkmen @PGijsbers @tonyhoo (#4744, #4785, #4822, #4860, #4891, #5012, #5047)
表格数据¶
移除的模型¶
移除了 vowpalwabbit 模型 (key:
VW) 和可选依赖项 (autogluon.tabular[vowpalwabbit]),因为 AutoGluon 中实现的该模型使用不广泛,且基本处于无人维护状态。 @Innixma (#4975)移除了 TabTransformer 模型 (key:
TRANSF),因为 AutoGluon 中实现的该模型已严重过时,自 2020 年以来无人维护,并且通常性能不如 FT-Transformer (key:FT_TRANSFORMER)。 @Innixma (#4976)移除了
autogluon.tabular[tests]安装中的 tabpfn,为未来支持tabpfn>=2.x做准备。 @Innixma (#4974)
新功能¶
添加
TabularPredictor.model_hyperparameters(model)方法,该方法返回模型的超参数。 @Innixma (#4901)添加
TabularPredictor.model_info(model)方法,该方法返回模型的元数据。 @Innixma (#4901)(实验性) 添加
plot_leaderboard.py以可视化预测器在训练时间上的性能。 @Innixma (#4907)(主要) 添加内部
ag_model_registry以改进对支持的模型族及其功能的跟踪。 @Innixma (#4913, #5057, #5107)添加
raise_on_model_failureTabularPredictor.fit参数,默认为 False。如果设置为 True,当模型在训练过程中抛出异常时将立即抛出原始异常,而不是继续下一个模型。在调试时,将此参数设置为 True 对于找出模型失败原因非常有帮助,因为否则异常会由 AutoGluon 处理,这在调试时不是期望的行为。 @Innixma (#4937, #5055)
文档¶
修复和改进¶
(主要) 确保 refit_full 中的 bagged refits 正常工作(在 v1.2.0 中由于错误而崩溃)。 @Innixma (#4870)
修复了 balanced_accuracy 指标的边缘情况异常 + 添加了单元测试以确保未来不会出现错误。 @Innixma (#4775)
改进了 CatBoost memory_check 回调中的日志记录和文档。 @celestinoxp (#4802)
改进了代码格式以满足 PEP585。 @celestinoxp (#4823)
(未来警告)
TabularPredictor.delete_models()在未来版本中将默认为dry_run=False(当前默认为dry_run=True)。请确保明确指定dry_run=True以便现有逻辑在未来版本中保持不变。 @Innixma (#4905)通过各种优化将表格数据单元测试速度提高了 4 倍 (3060 秒 -> 743 秒)。 @Innixma (#4944)
修复了当存在 categorical features 时
TabularPredictor.refit_full(train_data_extra)失败的问题。 @Innixma (#4948)将
convert_simulation_artifacts_to_tabular_predictions_dict创建的 artifact 内存使用量减少了 4 倍。 @Innixma (#5024)
时间序列¶
新的 v1.3 版本为时间序列模块带来了许多可用性改进和错误修复。在内部,我们完成了对核心类的重大重构,并引入了静态类型检查,以简化未来的贡献、加速开发并及早发现潜在错误。
API 变更和弃用¶
作为重构的一部分,我们对内部
AbstractTimeSeriesModel类进行了一些更改。如果您维护着 自定义模型 的实现,您可能需要进行更新。请参考 自定义预测模型教程 了解详细信息。仅依赖
timeseries模块公共 API(TimeSeriesPredictor和TimeSeriesDataFrame)的用户无需执行任何操作。
新功能¶
由 @abdulfatir 贡献的在
evaluate和leaderboard中添加cutoff支持 #5078由 @shchur 贡献的为
TimeSeriesPredictor添加horizon_weight支持 #5084由 @shchur 贡献的为 TimeSeriesPredictor 添加
make_future_data_frame方法 #5051由 @canerturkmen 贡献的重构 ensemble 基类并添加新的 ensembles #5062
代码质量¶
修复和改进¶
由 @canerturkmen 贡献的修复使用
covariate_regressor的模型的特征重要性计算问题 #4845由 @abdulfatir @shchur 贡献的修复 Chronos 和其他模型的超参数调优问题 #4838 #5075 #5079
由 @abdulfatir @shchur 贡献的修复
TimeSeriesDataFrame的频率推断问题 #4834 #5066由 @Killer3048 贡献的更新自定义
distr_output的文档 #5068Chronos-Bolt:由 @abdulfatir 贡献的修复影响常数序列的缩放问题 #5013
由 @abdulfatir 贡献的修复
transformers中已弃用的evaluation_strategykwarg #5019由 @canerturkmen 贡献的重命名 covariate metadata #5064
多模态¶
新功能¶
AutoGluon 的 MultiModal 模块通过一项全面的“技巧集合”更新得到增强,该更新通过先进的融合技术、数据增强和集成的集成学习器,显著提高了处理图像、文本和表格数据组合时的性能。在遵循此处的说明下载检查点后,现在可以通过简单的 use_ensemble=True 参数访问这些功能。
[AutoMM] 由 @zhiqiangdon 贡献的技巧集合 #4737
文档¶
[教程] 由 @cheungdaven 贡献的 categorical convert_to_text 默认值 #4699
[AutoMM] 由 @FANGAreNotGnu 贡献的修复和更新目标检测教程 #4889
修复和改进¶
由 @FANGAreNotGnu 贡献的修复目标检测教程和 predict 的默认行为 #4865
由 @k-ken-t4g 贡献的修复下载函数中的 NLTK tagger 路径问题 #4982
特别致谢¶
Zhiqiang Tang,他为 AutoGluon 的 MultiModal 实现了“技巧集合”,显著提升了多模态性能。
Caner Turkmen,他主导了时间序列模块
timeseries内部逻辑的重构和改进工作。Celestino,作为新贡献者提供了大量错误报告、建议和代码清理工作。
贡献者¶
完整贡献者列表(按提交数量排序)
@Innixma @shchur @canerturkmen @tonyhoo @abdulfatir @celestinoxp @suzhoum @FANGAreNotGnu @prateekdesai04 @zhiqiangdon @cheungdaven @LennartPurucker @abhishek-iitmadras @zkalson @nathanaelbosch @Killer3048 @FireballDWF @timostrunk @everdark @kbulygin @PGijsbers @k-ken-t4g
新贡献者¶
@celestinoxp 在 #4796 中做出了首次贡献
@PGijsbers 在 #4891 中做出了首次贡献
@k-ken-t4g 在 #4982 中做出了首次贡献
@FireballDWF 在 #5000 中做出了首次贡献
@Killer3048 在 #5068 中做出了首次贡献