最新消息¶
您可以在此处找到 AutoGluon 当前和过去版本的发布说明。
v1.3.0
版本 1.3.0
我们很高兴地宣布 AutoGluon 1.3.0 版本发布!
AutoGluon 1.3 版本侧重于稳定性和易用性改进、错误修复和依赖项升级。
此版本包含来自 20 位贡献者的 142 次提交!请在此处查看完整的提交变更日志:https://github.com/autogluon/autogluon/compare/v1.2.0…v1.3.0
加入社区:

不支持加载在旧版本 AutoGluon 上训练的模型。请使用 AutoGluon 1.3 重新训练模型。
亮点
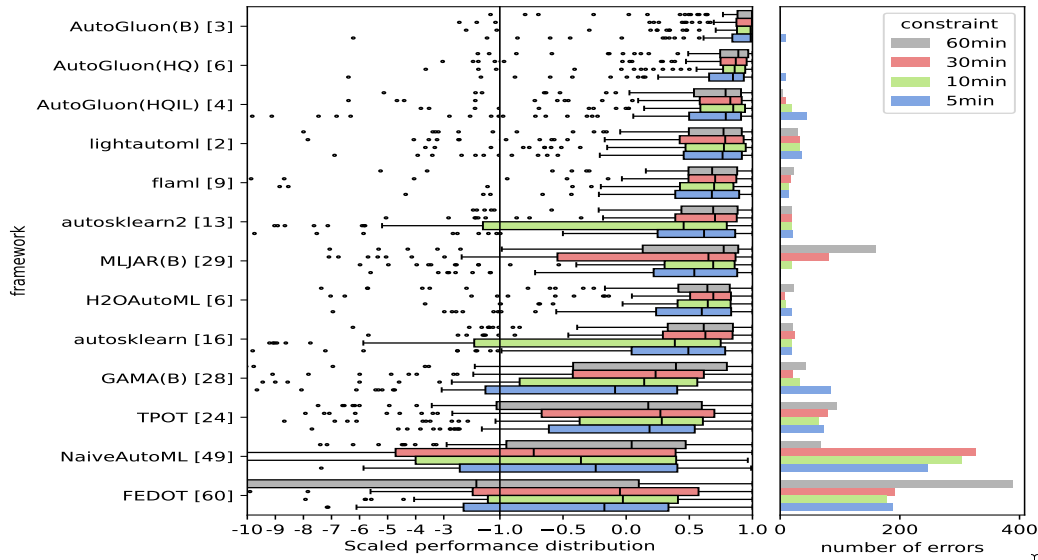
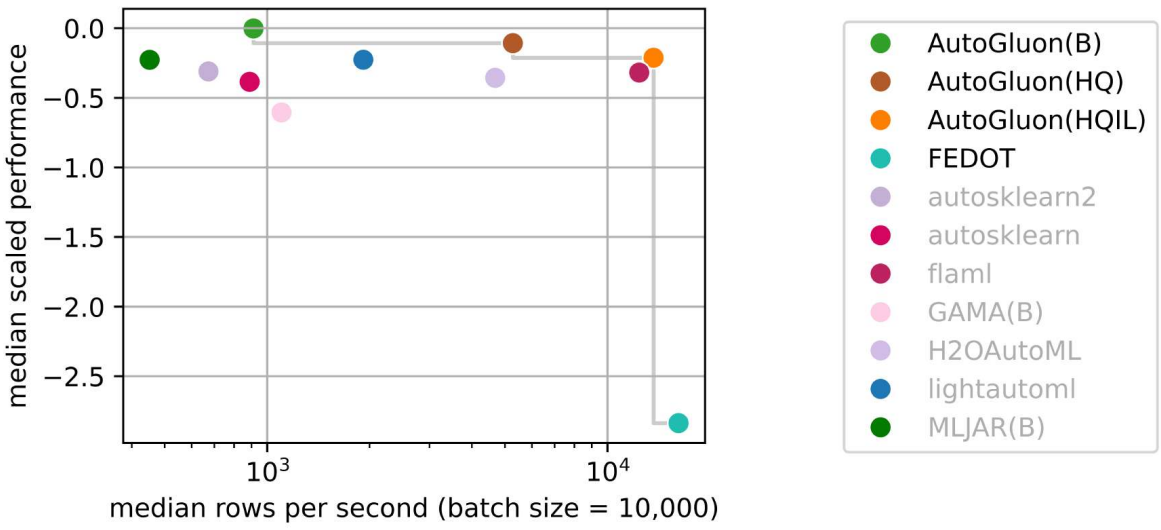
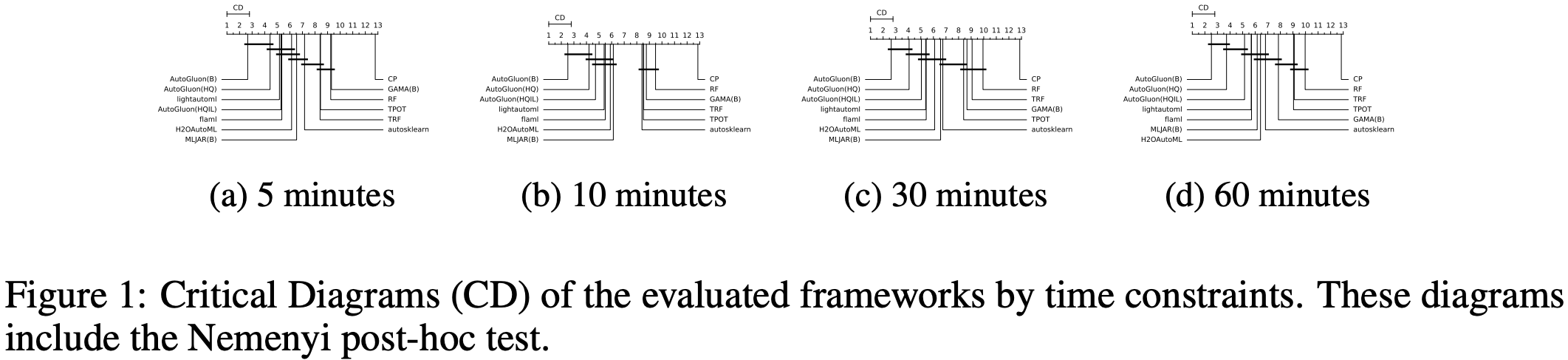
AutoGluon-Tabular 在 2025 年 AutoML Benchmark 中处于领先地位!
AutoML Benchmark 2025 是一项针对表格 AutoML 框架的独立大规模评估,展示了 AutoGluon 1.2 作为最先进的 AutoML 框架!亮点包括:
通过 Nemenyi 后验检验,在所有时间限制下,AutoGluon 的排名在统计学上显著优于所有 AutoML 系统。
AutoGluon 在 5 分钟训练预算下优于所有其他具有 1 小时训练预算的 AutoML 系统。
AutoGluon 在所有评估的预设和时间限制下,在质量和速度方面都具有帕累托效率。
AutoGluon 在使用
presets="high", infer_limit=0.0001(图中的 HQIL) 时,推理吞吐量达到 >10,000 样本/秒,同时性能优于所有其他方法。AutoGluon 是最稳定的 AutoML 系统。对于“best”和“high”预设,AutoGluon 在所有 >5 分钟的时间预算下均未发生故障。
AutoGluon 多模态的“技巧集”更新
我们很高兴地宣布 AutoGluon 多模态(AutoMM)集成了全面的“技巧集”更新。这项重大增强功能在处理图像、文本和表格数据组合时,显著提高了多模态 AutoML 的性能。此次更新实现了多种策略,包括多模态模型融合技术、多模态数据增强、跨模态对齐、表格数据序列化、更好地处理缺失模态,以及一个集成这些技术的集成学习器,以实现最佳性能。
用户现在可以通过初始化 MultiModalPredictor 时的简单参数来访问这些功能,具体方法请遵循此处的说明下载检查点。
from autogluon.multimodal import MultiModalPredictor
predictor = MultiModalPredictor(label="label", use_ensemble=True)
predictor.fit(train_data=train_data)
我们感谢 @zhiqiangdon 提供了这项重要贡献,增强了 AutoGluon 处理复杂多模态数据集的能力。以下是描述技术细节的相应研究论文:Bag of Tricks for Multimodal AutoML with Image, Text, and Tabular Data。
弃用和重大变更
以下已弃用的 TabularPredictor 方法已在 1.3.0 版本中移除(在 1.0.0 中弃用,在 1.2.0 中引发错误,在 1.3.0 中移除)。请使用新名称:
persist_models->persist,unpersist_models->unpersist,get_model_names->model_names,get_model_best->model_best,get_pred_from_proba->predict_from_proba,get_model_full_dict->model_refit_map,get_oof_pred_proba->predict_proba_oof,get_oof_pred->predict_oof,get_size_disk_per_file->disk_usage_per_file,get_size_disk->disk_usage,get_model_names_persisted->model_names(persisted=True)
以下逻辑已在 1.3.0 版本中开始弃用,并将记录 FutureWarning。功能将在未来版本中更改:
(FutureWarning)
TabularPredictor.delete_models()在未来版本中将默认设置为dry_run=False(目前为dry_run=True)。为了在未来版本中保留现有逻辑,请确保您显式指定dry_run=True。@Innixma (#4905)
一般
改进
(重大) 重构
AbstractTrainer类的内部结构,以提高可扩展性并减少代码重复。@canerturkmen (#4804, #4820, #4851)
依赖项
更新 numpy 到
>=1.25.0,<2.3.0。@tonyhoo, @Innixma, @suzhoum (#5020, #5056, #5072)更新 scikit-learn 到
>=1.4.0,<1.7.0。@tonyhoo, @Innixma (#5029, #5045)更新 ray 到
>=2.10.0,<2.45。@suzhoum, @celestinoxp, @tonyhoo (#4714, #4887, #5020)更新 torch 到
>=2.2,<2.7。@FireballDWF (#5000)更新 lightning 到
>=2.2,<2.7。@FireballDWF (#5000)更新 torchmetrics 到
>=1.2.0,<1.8。@zkalson, @tonyhoo (#4720, #5020)更新 torchvision 到
>=0.16.0,<0.22.0。@FireballDWF (#5000)更新 accelerate 到
>=0.34.0,<2.0。@FireballDWF (#5000)
文档
更新 CONTRIBUTING.md 中记录的 python 版本。@celestinoxp (#4796)
修复各种拼写错误。@celestinoxp (#4819)
修复和改进
确保当
path_suffix != None且path=None时,setup_outputdir始终创建一个新目录。@Innixma (#4903)在调用
cuda.device_count()之前检查cuda.is_available()以避免警告。@Innixma (#4902)修复
get_approximate_df_mem_usage中罕见的 ZeroDivisionError 边缘情况。@shchur (#5083)小幅修复和改进。@suzhoum @Innixma @canerturkmen @PGijsbers @tonyhoo (#4744, #4785, #4822, #4860, #4891, #5012, #5047)
表格数据
移除的模型
移除了 vowpalwabbit 模型(键:
VW)和可选依赖项(autogluon.tabular[vowpalwabbit]),因为 AutoGluon 中实现的此模型使用不广泛且基本未维护。@Innixma (#4975)移除了 TabTransformer 模型(键:
TRANSF),因为 AutoGluon 中实现的此模型严重过时,自 2020 年以来未维护,且通常性能不如 FT-Transformer(键:FT_TRANSFORMER)。@Innixma (#4976)在准备未来支持
tabpfn>=2.x时,从autogluon.tabular[tests]安装中移除了 tabpfn。@Innixma (#4974)
新功能
添加
TabularPredictor.model_hyperparameters(model)方法,用于返回模型的超参数。@Innixma (#4901)添加
TabularPredictor.model_info(model)方法,用于返回模型的元数据。@Innixma (#4901)(实验性) 添加
plot_leaderboard.py,用于可视化预测器在训练时间上的性能。@Innixma (#4907)(重大) 添加内部
ag_model_registry,以改进对支持的模型系列及其能力的跟踪。@Innixma (#4913, #5057, #5107)添加
raise_on_model_failure参数到TabularPredictor.fit,默认为 False。如果设置为 True,则当模型在拟合过程中引发异常时,将立即抛出原始异常,而不是继续下一个模型。在调试时,如果试图找出模型失败的原因,将其设置为 True 会非常有帮助,因为否则异常会被 AutoGluon 处理,这在调试时是不希望的。@Innixma (#4937, #5055)
文档
修复和改进
(重大) 确保 refit_full 中的 bagged refits 正常工作(v1.2.0 中因 bug 崩溃)。@Innixma (#4870)
修复 balanced_accuracy 指标的边缘情况异常 + 添加单元测试以确保未来不会出现 bug。@Innixma (#4775)
改进 CatBoost memory_check 回调中的日志记录和文档。@celestinoxp (#4802)
改进代码格式以满足 PEP585。@celestinoxp (#4823)
(FutureWarning)
TabularPredictor.delete_models()在未来版本中将默认设置为dry_run=False(目前为dry_run=True)。为了在未来版本中保留现有逻辑,请确保您显式指定dry_run=True。@Innixma (#4905)修复当存在分类特征时
TabularPredictor.refit_full(train_data_extra)失败的问题。@Innixma (#4948)将
convert_simulation_artifacts_to_tabular_predictions_dict创建的 artifact 内存使用量减少了 4 倍。@Innixma (#5024)
时间序列
新的 v1.3 版本为 TimeSeries 模块带来了众多易用性改进和 bug 修复。在内部,我们完成了核心类的重大重构,并引入了静态类型检查,以简化未来的贡献、加速开发并及早发现潜在 bug。
API 变更和弃用
作为重构的一部分,我们对内部
AbstractTimeSeriesModel类进行了多项更改。如果您维护着 自定义模型 实现,则可能需要对其进行更新。有关详细信息,请参阅自定义预测模型教程。仅依赖
timeseries模块的公共 API(TimeSeriesPredictor和TimeSeriesDataFrame)的用户无需执行任何操作。
新功能
由 @abdulfatir 在 #5078 中添加了对
evaluate和leaderboard中cutoff的支持由 @shchur 在 #5084 中为
TimeSeriesPredictor添加了对horizon_weight的支持由 @shchur 在 #5051 中向 TimeSeriesPredictor 添加了
make_future_data_frame方法由 @canerturkmen 在 #5062 中重构了集成基础类并添加了新的集成
代码质量
由 @canerturkmen 在 #4712 #4788 #4801 #4821 #4969 #5086 #5085 中为
timeseries模块添加了静态类型检查由 @canerturkmen 在 #4868 #4909 #4946 #4958 #5008 #5038 中重构了
AbstractTimeSeriesModel类由 @canerturkmen 在 #4773 #4828 #4877 #4872 #4884 #4888 中改进了单元测试
修复和改进
由 @canerturkmen 在 #4845 中修复了使用
covariate_regressor的模型的特征重要性计算由 @abdulfatir @shchur 在 #4838 #5075 #5079 中修复了 Chronos 和其他模型的超参数调优
由 @abdulfatir @shchur 在 #4834 #5066 中修复了
TimeSeriesDataFrame的频率推断更新自定义
distr_output的文档,由 @Killer3048 在 #5068 中完成Chronos-Bolt: 修复影响常数序列的缩放问题,由 @abdulfatir 在 #5013 中完成
修复
transformers中已弃用的evaluation_strategykwarg,由 @abdulfatir 在 #5019 中完成重命名协变量元数据,由 @canerturkmen 在 #5064 中完成
如果向
TimeSeriesPredictor提供了 S3 路径,则发出警告,由 @shchur 在 #5091 中完成
多模态
新功能
AutoGluon 的 MultiModal 模块已通过全面的“技巧集”(Bag of Tricks) 更新得到增强,该更新通过先进的融合技术、数据增强以及现在通过简单的 use_ensemble=True 参数即可访问的集成学习器,显著提高了处理图像、文本和表格数据组合时的性能。请按照这里的说明下载 checkpoints。
[AutoMM] 技巧集 (Bag of Tricks),由 @zhiqiangdon 在 #4737 中完成
文档
[教程] categorical convert_to_text 默认值,由 @cheungdaven 在 #4699 中完成
[AutoMM] 修复和更新对象检测教程,由 @FANGAreNotGnu 在 #4889 中完成
修复和改进
修复对象检测教程和 predict 的默认行为,由 @FANGAreNotGnu 在 #4865 中完成
修复下载函数中的 NLTK tagger 路径,由 @k-ken-t4g 在 #4982 中完成
特别感谢
Zhiqiang Tang 实现了 AutoGluon MultiModal 的“技巧集”(Bag of Tricks),显著提升了多模态性能。
Caner Turkmen 领导了
timeseries模块内部逻辑的重构和改进工作。Celestino 作为新贡献者,提供了大量错误报告、建议和代码清理。
贡献者
完整贡献者列表(按提交数量排序)
@Innixma @shchur @canerturkmen @tonyhoo @abdulfatir @celestinoxp @suzhoum @FANGAreNotGnu @prateekdesai04 @zhiqiangdon @cheungdaven @LennartPurucker @abhishek-iitmadras @zkalson @nathanaelbosch @Killer3048 @FireballDWF @timostrunk @everdark @kbulygin @PGijsbers @k-ken-t4g
新贡献者
@celestinoxp 在 #4796 中做出了首次贡献
@PGijsbers 在 #4891 中做出了首次贡献
@k-ken-t4g 在 #4982 中做出了首次贡献
@FireballDWF 在 #5000 中做出了首次贡献
@Killer3048 在 #5068 中做出了首次贡献
v1.2.0
版本 1.2.0
我们很高兴地宣布 AutoGluon 1.2.0 发布。
AutoGluon 1.2 包含对 Tabular 和 TimeSeries 模块的巨大改进,每个模块相较于 AutoGluon 1.1 取得了 70% 的胜率。此版本还新增了对 Python 3.12 的支持,并取消了对 Python 3.8 的支持。
此版本包含来自 19 位贡献者的 186 个提交!在此查看完整的提交变更日志:https://github.com/autogluon/autogluon/compare/v1.1.1…v1.2.0
加入社区:
获取最新动态:
不支持加载在旧版本 AutoGluon 上训练的模型。请使用 AutoGluon 1.2 重新训练模型。
对于 Tabular 模块,我们将新的 TabPFNMix 表格基础模型和并行训练策略的主要增强功能整合到新的 "experimental_quality" 预设中,以确保希望尝试尖端新功能的用户能顺利过渡。我们将利用此版本在将这些功能集成到其他预设之前收集反馈。我们还引入了一种新的堆叠层模型剪枝技术,可在小数据集上实现 3 倍的推理加速,同时性能零损失,并显著改善了整体后处理校准,尤其是在小数据集上。
对于 TimeSeries 模块,我们引入了 Chronos-Bolt,这是我们集成到 AutoGluon 中的最新基础模型,与 Chronos 相比,它在准确性和推理速度方面都有巨大改进,并提供了微调功能。我们还增加了协变量回归器支持!
我们也很高兴地宣布 AutoGluon-Assistant (AG-A),这是我们在自动化数据科学领域的首次尝试。
更多详情请见下面的聚焦部分!
聚焦
AutoGluon 成为 2024 年竞赛机器学习的黄金标准
在深入探讨 1.2 的新功能之前,我们想首先强调 AutoGluon 在 2024 年 Kaggle 等竞赛机器学习网站上获得的广泛采用。在 2024 年全年,AutoGluon 在 18 个表格 Kaggle 竞赛中,有 15 个实现了前 3 名的成绩,其中包括 7 个第一名,并且从未跌出私人排行榜的前 1%,每个竞赛平均有超过 1000 支人类团队竞争。在奖金高达 75,000 美元的 2024 Kaggle AutoML 大奖赛中,第一名、第二名和第三名团队都使用了 AutoGluon,其中第二名团队由两位 AutoGluon 开发者:Lennart Purucker 和 Nick Erickson 领导!相比之下,在 2023 年,AutoGluon 只获得了一个第一名和一个第二名解决方案。我们将这种增长主要归功于 AutoGluon 1.0 及更高版本的改进。

我们想强调的是,这些结果是通过人类专家与 AutoGluon 和其他工具的交互实现的,通常包括手动特征工程和超参数调整,以充分发挥 AutoGluon 的优势。要查看所有 AutoGluon 解决方案在 Kaggle 上的实时排名,请参考我们的 AWESOME.md ML 竞赛部分,其中提供了所有解决方案报告的链接。
AutoGluon-Assistant:使用 AutoGluon 和 LLMs 自动化数据科学
我们很高兴分享新的 AutoGluon-Assistant 模块 (AG-A) 的发布,该模块由 AWS Bedrock 或 OpenAI 的 LLMs 提供支持。AutoGluon-Assistant 使用户能够仅通过自然语言描述来解决表格机器学习问题,通过我们简单的用户界面,无需编写任何代码。完全自主的 AG-A 在 Kaggle 竞赛中超越了 74% 的人类机器学习从业者,并以 Team AGA 🤖 的身份在奖金 75,000 美元的 2024 Kaggle AutoML 大奖赛中获得了实时前 10 名的成绩!
TabularPredictor 预设 = "experimental_quality"
TabularPredictor 有一个新的 "experimental_quality" 预设,它提供了比 "best_quality" 更好的预测质量。在 AutoMLBenchmark 上,我们在 64 核 CPU 机器上运行 4 小时的情况下观察到相对于 best_quality 有 70% 的胜率。此预设是用于测试尖端功能和模型的试验场,我们希望在未来的版本中将其整合到 best_quality 中。我们建议使用至少 16 核 CPU、64 GB 内存和 4 小时以上 time_limit 的机器,以便从 experimental_quality 中获得最大收益。如果您在运行 experimental_quality 预设时遇到任何问题,请通过 GitHub issue 告知我们。
TabPFNMix:表格数据的基础模型
TabPFNMix 是 AutoGluon 团队创建的第一个表格基础模型,并且完全在合成数据上进行了预训练。该模型构建在 TabPFN 和 TabForestPFN 的先前工作之上。据我们所知,TabPFNMix 在 1000 到 10000 个样本的数据集上实现了单个开源模型的最新性能,并且还支持回归任务!在 TabRepo 中小于或等于 10000 个训练样本的 109 个分类数据集上,微调后的 TabPFNMix 优于所有先前的模型,相对于最强的树模型 CatBoost 胜率为 64%,相对于微调后的 TabForestPFN 胜率为 61%。
该模型可通过 TABPFNMIX 超参数键使用,并在新的 experimental_quality 预设中使用。我们建议将此模型用于训练样本少于 50,000 个的数据集,最好具有较大的时间限制和 64GB+ 内存。这项工作仍处于早期阶段,我们感谢社区提供的任何反馈,以帮助我们在未来的版本中进行迭代和改进。您可以通过访问我们在 HuggingFace 上的模型页面了解更多信息(tabpfn-mix-1.0-classifier,tabpfn-mix-1.0-regressor)。如果您想看到更多内容,请在 HuggingFace 上给我们点赞!未来计划发表一篇论文,提供有关该模型的更多详细信息。
fit_strategy=”parallel”
AutoGluon 的 TabularPredictor 现在支持新的 fit 参数 fit_strategy 和新的 "parallel" 选项,该选项在新的 experimental_quality 预设中默认启用。对于具有 16 个或更多 CPU 核的机器,并行训练策略比先前的 "sequential" 策略提供了主要的加速。我们估计使用 64 个 CPU 核时,大多数数据集将体验到 2-4 倍的加速,并且随着 CPU 核数量的增加,加速效果也会更大。
Chronos-Bolt⚡:一个快 250 倍、更准确的 Chronos 模型
Chronos-Bolt 是我们集成到 AutoGluon 中的最新时间序列预测基础模型。它基于 T5 编码器-解码器架构,并在近 1000 亿个时间序列观测数据上进行了训练。它将历史时间序列上下文分成多个观测值的块,然后将其输入到编码器中。解码器随后使用这些表示直接生成多个未来步骤的分位数预测——这种方法称为直接多步预测。与相同大小的原始 Chronos 模型相比,Chronos-Bolt 模型速度提高了 250 倍,内存效率提高了 20 倍。
下图比较了 Chronos-Bolt 与原始 Chronos 模型在预测 1024 个时间序列时的推理时间,其中上下文长度为 512 个观测值,预测范围为 64 个步骤。

Chronos-Bolt 模型不仅显著更快,而且比原始 Chronos 模型更准确。下图报告了 Chronos-Bolt 的概率和点预测性能,分别以加权分位数损失 (WQL) 和平均绝对缩放误差 (MASE) 表示,并在 27 个数据集上进行了汇总(有关此基准的详细信息,请参阅Chronos 论文)。值得注意的是,尽管在训练期间没有接触过这些数据集,零样本 Chronos-Bolt 模型表现优于已在这些数据集上训练过的常用统计模型和深度学习模型(以 * 突出显示)。此外,它们的性能也优于其他基础模型(用 + 表示),这表明这些模型已在我们基准测试的某些数据集上进行了预训练,并非完全零样本。特别是,Chronos-Bolt (Base) 在预测准确性方面也超越了原始 Chronos (Large) 模型,同时速度快了 600 多倍。

Chronos-Bolt 模型现在可通过 AutoGluon 提供四种大小——Tiny (9M)、Mini (21M)、Small (48M) 和 Base (205M)——并且也可在 CPU 上使用。随着 Chronos-Bolt 模型和其他增强功能的加入,AutoGluon v1.2 相较于上一版本取得了 70%+ 的胜率!
除了新的 Chronos-Bolt 模型外,我们还增加了对 Chronos 和 Chronos-Bolt 模型进行轻松微调的支持。请查看更新的Chronos 教程,了解如何使用和微调 Chronos-Bolt 模型。
时间序列协变量回归器
我们为所有预测模型添加了协变量回归器支持。协变量回归器是表格回归模型,可以与单变量预测模型结合使用以纳入外部信息。这对于像 Chronos-Bolt 这样的基础模型特别有用,因为它们仅依赖目标时间序列的历史数据,无法直接使用外部信息(例如节假日或促销)。为了在协变量可用时改进单变量模型的预测,首先在已知协变量和静态特征上拟合一个协变量回归器,以预测每个时间步的目标列。然后将协变量回归器的预测结果从目标列中减去,单变量模型再预测残差。Chronos 教程展示了如何将协变量回归器与 Chronos-Bolt 结合使用。
一般
改进
依赖项
取消 Python 3.8 支持。@prateekdesai04 (#4512)
更新 scikit-learn 至
>=1.4.0,<1.5.3。@prateekdesai04 (#4420, #4570)更新 pyarrow 至
>=15.0.0。@prateekdesai04 (#4520)更新 psutil 至
>=5.7.3,<7.0.0。@prateekdesai04 (#4570)更新 Pillow 至
>=10.0.1,<12。@prateekdesai04 (#4570)更新 xgboost 至
>=1.6,<2.2。@prateekdesai04 (#4570)更新 timm 至
>=0.9.5,<1.0.7。@prateekdesai04 (#4580)更新 accelerate 至
>=0.34.0,<1.0。@cheungdaven @tonyhoo @shchur (#4596, #4612, #4676)
文档
修复和改进
将 DropDuplicatesFeatureGenerator 训练时间加快 2 倍以上。@shchur (#4543)
添加
compute_metric作为compute_weighted_metric的替代,提高项目兼容性。@Innixma (#4631)
表格数据
新功能
添加 TabPFNMix 模型。尝试使用
presets="experimental"。@xiyuanzh @Innixma (#4671, #4694)支持并行模型训练。尝试使用
fit_strategy="parallel"。@LennartPurucker @Innixma (#4606)学习曲线生成功能。@adibiasio @Innixma (#4411, #4635)
默认将
calibrate_decision_threshold设置为"auto",并改进决策阈值校准。这极大地改进了二分类中当eval_metric为f1和balanced_accuracy时的结果。@Innixma (#4632)添加自定义内存(软)限制支持。@LennartPurucker (#4333)
向模型添加
ag.compile超参数,以在训练时而不是使用predictor.compile进行编译。@Innixma (#4354)为 NN_TORCH 添加 AdaptiveES 支持,并将 max_epochs 从 500 增加到 1000,默认启用。@Innixma (#4436)
添加通过
delay_bag_setsfit 参数控制重复交叉验证行为的支持。默认设置为 False(之前为 True)。@LennartPurucker (#4552)将
positive_class作为 TabularPredictor 的初始化参数。@Innixma (#4445)
文档
添加了一个深入探讨 AutoGluon 工作原理的教程。@rey-allan (#4284)
修复和改进
(重大) 将 EnsembleSelection 的训练速度加快 2 倍以上。@nathanaelbosch (#4367)
(重大) 通过使用最佳迭代而不是最后一次迭代的温度,显著提高了温度缩放性能。@LennartPurucker (#4396)
(重大) 修复
roc_auc指标,使其在多分类中使用macro而非weighted。@LennartPurucker (#4407)(重大) 确保
refit_full尊重用户指定的num_cpus和num_gpus。@Innixma (#4495)(重大) 重构 TabularDataset。现在,TabularDataset 初始化时将始终返回一个 pandas DataFrame 对象,以简化各种文档并提高 IDE 调试可视化兼容性。@Innixma (#4613)
默认设置
num_bag_sets=1,以避免用户不使用预设且设置num_bag_folds>=2时使用num_bag_sets>1。@Innixma (#4446)修复 NN_TORCH 中
model.score调用时不小心更新 torch seed 的问题。@adibiasio (#4391)添加
raise_on_no_models_fitted开关,控制当没有模型拟合时 AutoGluon 是否报错。@LennartPurucker (#4389)默认设置
raise_on_no_models_fitted=True。在之前的版本中为 False。@Innixma (#4400)提高
predictor.predict_proba_multi在边缘情况下的可靠性。@Innixma (#4527)修复在处理标签列时(如果它是包含某个类别 0 个实例的 pandas category dtype)的边缘情况崩溃问题。@Innixma (#4583)
启用 aarch64 平台构建。@abhishek-iitmadras (#4663)
次要修复。@Innixma @LennartPurucker @shchur @rsj123 (#4224, #4317, #4335, #4352, #4353, #4379, #4384, #4474, #4485, #4675, #4682, #4700)
次要单元测试、文档和清理。@Innixma @abhishek-iitmadras (#4398, #4399, #4402, #4498, #4546, #4547, #4549, #4687, #4690, #4692)
时间序列
新功能
为 Chronos 和 Chronos-Bolt 模型添加微调支持 @abdulfatir (#4608, #4645, #4653, #4655, #4659, #4661, #4673, #4677)
添加 Chronos-Bolt @canerturkmen (#4625)
TimeSeriesPredictor.leaderboard现在可以计算额外指标并返回每个模型的超参数 @shchur (#4481)添加将 TimeSeriesDataFrame 转换为常规 pd.DataFrame 的方法 @shchur (#4415)
修复和改进
将 statsforecast 版本提升至 1.7 @canerturkmen @shchur (#4194, #4357)
加快 TimeSeriesFeatureGenerator 预处理逻辑的速度并减少内存使用 @shchur (#4557)
重构 GluonTS 默认参数处理,更新 TiDE 参数 @canerturkmen (#4640)
精简时间序列单元测试和冒烟测试 @canerturkmen (#4650)
次要修复 @abdulfatir @canerturkmen @shchur (#4259, #4299, #4395, #4386, #4409, #4533, #4565, #4633, #4647)
多模态
修复和改进
修复模型在检查点融合阶段失败后恢复时缺失验证指标的问题,由 @FANGAreNotGnu 在 https://github.com/autogluon/autogluon/pull/4449 中完成
添加 coco_root 以更好地支持 COCO 格式的自定义数据集。由 @FANGAreNotGnu 在 https://github.com/autogluon/autogluon/pull/3809 中完成
添加 COCO 格式保存支持并更新对象检测 I/O 处理,由 @FANGAreNotGnu 在 https://github.com/autogluon/autogluon/pull/3811 中完成
在使用 bandit 检查时跳过 MMDet 配置文件,由 @FANGAreNotGnu 在 https://github.com/autogluon/autogluon/pull/4630 中完成
修复 Logloss 错误并优化 Compute Score 逻辑,由 @FANGAreNotGnu 在 https://github.com/autogluon/autogluon/pull/4629 中完成
修复教程中的索引拼写错误,由 @FANGAreNotGnu 在 https://github.com/autogluon/autogluon/pull/4642 中完成
修复多分类的 Proba 指标,由 @FANGAreNotGnu 在 https://github.com/autogluon/autogluon/pull/4643 中完成
支持 torch 2.4,由 @tonyhoo 在 https://github.com/autogluon/autogluon/pull/4360 中完成
在教程中添加对象检测安装指南,由 @FANGAreNotGnu 在 https://github.com/autogluon/autogluon/pull/4430 中完成
添加 Bandit 警告缓解措施,用于内部
torch.save和torch.load的使用,由 @tonyhoo 在 https://github.com/autogluon/autogluon/pull/4502 中完成更新 accelerate 版本范围,由 @cheungdaven 在 https://github.com/autogluon/autogluon/pull/4596 中完成
绑定 nltk 版本以避免冗长的日志记录问题,由 @tonyhoo 在 https://github.com/autogluon/autogluon/pull/4604 中完成
升级 TIMM,由 @prateekdesai04 在 https://github.com/autogluon/autogluon/pull/4580 中完成
v1.2 版本中 _setup_utils.py 的关键依赖更新,由 @tonyhoo 在 https://github.com/autogluon/autogluon/pull/4612 中完成
每个 HPO 试验可配置的检查点保留数量,由 @FANGAreNotGnu 在 https://github.com/autogluon/autogluon/pull/4615 中完成
重构每种问题类型的指标,由 @FANGAreNotGnu 在 https://github.com/autogluon/autogluon/pull/4616 中完成
修复对象检测的 Torch 版本和 Colab 安装问题,由 @FANGAreNotGnu 在 https://github.com/autogluon/autogluon/pull/4447 中完成
特别感谢
Xiyuan Zhang 领导了 TabPFNMix 的开发!
TabPFN 的作者 Noah Hollmann, Samuel Muller, Katharina Eggensperger 和 Frank Hutter 解锁了表格数据基础模型的潜力,以及 TabForestPFN 的作者 Felix den Breejen, Sangmin Bae, Stephen Cha 和 Se-Young Yun 将这个想法扩展到更通用的表示。我们的 TabPFNMix 工作站在巨人的肩膀上。
Lennart Purucker 领导了并行模型训练功能的开发,并在 2024 Kaggle AutoML 大奖赛中将 AutoGluon 发挥到极致。
Robert Hatch, Tilii, Optimistix, Mart Preusse, Ravi Ramakrishnan, Samvel Kocharyan, Kirderf, Carl McBride Ellis, Konstantin Dmitriev 以及其他贡献者,感谢他们的富有洞察力的讨论以及在 Kaggle 上支持 AutoGluon!
Eddie Bergman 对表格回调支持功能进行了富有洞察力的意外代码审查。
贡献者
完整贡献者列表(按提交数量排序)
@Innixma @shchur @prateekdesai04 @tonyhoo @FangAreNotGnu @suzhoum @abdulfatir @canerturkmen @LennartPurucker @abhishek-iitmadras @adibiasio @rsj123 @nathanaelbosch @cheungdaven @lostella @zkalson @rey-allan @echowve @xiyuanzh
新贡献者
@nathanaelbosch 在 https://github.com/autogluon/autogluon/pull/4366 中做出了首次贡献
@adibiasio 在 https://github.com/autogluon/autogluon/pull/4391 中做出了首次贡献
@abdulfatir 在 https://github.com/autogluon/autogluon/pull/4608 中做出了首次贡献
@echowve 在 https://github.com/autogluon/autogluon/pull/4667 中做出了首次贡献
@abhishek-iitmadras 在 https://github.com/autogluon/autogluon/pull/4685 中做出了首次贡献
@xiyuanzh 在 https://github.com/autogluon/autogluon/pull/4694 中做出了首次贡献
v1.1.1
版本 1.1.1
我们很高兴地宣布 AutoGluon 1.1.1 发布。
AutoGluon 1.1.1 包含对 Tabular、TimeSeries 和 Multimodal 模块的错误修复和日志记录改进,以及对 PyTorch 2.2 和 2.3 的支持。
加入社区:
获取最新动态:
此版本支持 Python 3.8、3.9、3.10 和 3.11 版本。不支持加载在旧版本 AutoGluon 上训练的模型。请使用 AutoGluon 1.1.1 重新训练模型。
此版本包含来自 10 位贡献者的 52 个提交!
一般
新增对 PyTorch 2.2 的支持。@prateekdesai04 (#4123)
表格数据
注意:由于 model-interals.pkl 路径的修复,尝试加载使用先前 AutoGluon 版本训练的带有 FastAI 模型的 TabularPredictor 将在调用 predict 时引发异常。请确保版本匹配。
时间序列
修复 Chronos 推理中的 off-by-one 错误。@canerturkmen (#4205)
多模态
修复 CLIP 图像特征归一化中的错误。@Harry-zzh (#4114)
修复文本增强中的错误。@Harry-zzh (#4115)
修改默认微调技巧。@Harry-zzh (#4166)
为对象检测添加 PyTorch 版本警告。@FANGAreNotGnu (#4217)
文档和 CI
将竞赛解决方案添加到 AWESOME.md。@Innixma @shchur (#4122, #4163, #4245)
修复 PDF 分类教程。@zhiqiangdon (#4127)
添加 AutoMM 论文引用。@zhiqiangdon (#4154)
各种次要文档和测试修复及改进。@tonyhoo @shchur @lovvge @Innixma @suzhoum (#4113, #4176, #4225, #4233, #4235, #4249, #4266)
贡献者
完整贡献者列表(按提交数量排序)
@Innixma @shchur @Harry-zzh @suzhoum @zhiqiangdon @lovvge @rey-allan @prateekdesai04 @canerturkmen @FANGAreNotGnu
新贡献者
@lovvge 在 https://github.com/autogluon/autogluon/commit/57a15fcfbbbc94514ff20ed2774cd447d9f4115f 中做出了首次贡献
@rey-allan 在 #4145 中做出了首次贡献
v1.1.0
版本 1.1.0
我们很高兴地宣布 AutoGluon 1.1 发布。
AutoGluon 1.1 包含对 TimeSeries 模块的重大改进,通过添加预训练的时间序列预测模型 Chronos 以及众多其他增强功能,相较于 AutoGluon 1.0 取得了 60% 的胜率。其他模块也通过新增功能(如 Conv-LORA 支持)以及改进对 5 - 30 GB 大小的大型表格数据集的性能得到了增强。有关 AutoGluon 1.1 功能的完整详细信息,请参阅下面的功能亮点和逐项增强功能。
加入社区:
获取最新动态:
此版本支持 Python 3.8、3.9、3.10 和 3.11 版本。不支持加载在旧版本 AutoGluon 上训练的模型。请使用 AutoGluon 1.1 重新训练模型。
此版本包含来自 20 位贡献者的 121 个提交!
完整贡献者列表(按提交数量排序)
@shchur @prateekdesai04 @Innixma @canerturkmen @zhiqiangdon @tonyhoo @AnirudhDagar @Harry-zzh @suzhoum @FANGAreNotGnu @nimasteryang @lostella @dassaswat @afmkt @npepin-hub @mglowacki100 @ddelange @LennartPurucker @taoyang1122 @gradientsky
特别感谢 @ddelange 在 Python 3.11 支持和 Ray 版本升级方面的持续帮助!
聚焦
AutoGluon 在机器学习竞赛中屡获佳绩!
自 AutoGluon 1.0 发布以来,AutoGluon 在 Kaggle 上获得了广泛采用。在过去 90 天里,AutoGluon 已在超过 130 个 Kaggle notebook 中使用,并在超过 100 个讨论帖子中提及!最令人兴奋的是,自 2024 年初以来,AutoGluon 已在多个拥有数千名参赛者的竞赛中获得顶级排名。
排名 |
竞赛 |
作者 |
日期 |
AutoGluon 详情 |
备注 |
|---|---|---|---|---|---|
:3rd_place_medal: 排名 3/2303 (前 0.1%) |
2024/03/31 |
v1.0, Tabular |
Kaggle Playground 系列 S4E3 |
||
:2nd_place_medal: 排名 2/93 (前 2%) |
2024/03/21 |
v1.0, Tabular |
|||
:2nd_place_medal: 排名 2/1542 (前 0.1%) |
2024/03/01 |
v1.0, Tabular |
|||
:2nd_place_medal: 排名 2/3746 (前 0.1%) |
2024/02/29 |
v1.0, Tabular |
Kaggle Playground 系列 S4E2 |
||
:2nd_place_medal: 排名 2/3777 (前 0.1%) |
2024/01/31 |
v1.0, Tabular |
Kaggle Playground 系列 S4E1 |
||
排名 4/1718 (前 0.2%) |
2024/01/01 |
v1.0, Tabular |
Kaggle Playground 系列 S3E26 |
我们很高兴看到数据科学社区正在利用 AutoGluon 作为他们快速有效地实现顶级 ML 解决方案的首选方法!有关使用 AutoGluon 的竞赛解决方案的最新列表,请参阅我们的 AWESOME.md,如果您在竞赛中使用了 AutoGluon,请随时告诉我们!
Chronos,一个用于时间序列预测的预训练模型
AutoGluon-TimeSeries 现在引入了 Chronos,这是一系列在大量开源时间序列数据集上预训练的预测模型,可以为新的未见数据生成准确的零样本预测。查看新教程,了解如何通过熟悉的 TimeSeriesPredictor API 使用 Chronos。
一般
PyTorch, CUDA, Lightning 版本升级。 @prateekdesai04 @canerturkmen @zhiqiangdon (#3982, #3984, #3991, #4006)
Scikit-learn 版本升级。 @prateekdesai04 (#3872, #3881, #3947)
时间序列
亮点
AutoGluon 1.1 带来了时间序列模块的众多新功能和改进。这些功能包括急需的功能,例如特征重要性、对分类协变量的支持、预测结果可视化能力以及日志记录增强。新版本还在预测准确性方面取得了显著提升,与之前的 AutoGluon 版本相比,胜率达到 60%,平均误差减少 3%。这些改进主要归因于 Chronos 的增加、改进的预处理逻辑以及原生缺失值处理。
新功能
添加 Chronos 预训练预测模型(教程)。 @canerturkmen @shchur @lostella (#3978, #4013, #4052, #4055, #4056, #4061, #4092, #4098)
使用
TimeSeriesPredictor.feature_importance()衡量特征和协变量对预测准确性的重要性。 @canerturkmen (#4033, #4087)使用
TimeSeriesPredictor.persist()将模型保留在内存中,从而提高推理速度。 @canerturkmen (#4005)添加
RMSLE评估指标。 @canerturkmen (#3938)启用文件日志记录。 @canerturkmen (#3877)
添加选项,使用
keep_lightning_logs超参数在训练后保留 lightning 日志。 @shchur (#3937)
修复和改进
修复不一致的随机种子。 @canerturkmen @shchur (#3934, #4099)
小幅修复。 @canerturkmen, @shchur, @AnirudhDagar (#4009, #4040, #4041, #4051, #4070, #4094)
AutoMM
亮点
AutoMM 1.1 引入了创新的 Conv-LoRA,这是一种参数高效微调 (PEFT) 方法,源自我们在 ICLR 2024 上发表的最新论文,题为“卷积遇到 LoRA:Segment Anything Model 的参数高效微调”。Conv-LoRA 专为微调 Segment Anything Model 设计,在包括自然图像、农业、遥感和医疗健康在内的各种领域的语义分割任务中,与之前的 PEFT 方法(如 LoRA 和视觉提示调优)相比,表现出卓越的性能。查看我们的 Conv-LoRA 示例。
新功能
添加了 Conv-LoRA,一种新的参数高效微调方法。 @Harry-zzh @zhiqiangdon (#3933, #3999, #4007, #4022, #4025)
添加了对新列类型 ‘image_base64_str’ 的支持。 @Harry-zzh @zhiqiangdon (#3867)
添加了对在 FT-Transformer 中加载预训练权重的支持。 @taoyang1122 @zhiqiangdon (#3859)
修复和改进
修复了语义分割中的 bug。 @Harry-zzh (#3801, #3812)
修复了 PEFT 方法中的 bug。 @Harry-zzh (#3840)
对于 high_quality 和 best_quality 预设,将对象检测训练速度提升了约 30%。 @FANGAreNotGnu (#3970)
弃用 Grounding-DINO @FANGAreNotGnu (#3974)
修复了 lightning 升级问题 @zhiqiangdon (#3991)
修复了在知识蒸馏中使用 f1, f1_macro, f1_micro 进行二元分类的问题。 @nimasteryang (#3837)
由于许可证问题,从安装中移除了 MyMuPDF。用户需要自行安装才能进行文档分类。 @zhiqiangdon (#4093)
表格数据
亮点
AutoGluon-Tabular 1.1 主要侧重于 bug 修复和稳定性改进。特别是,通过使用子采样进行决策阈值校准以及对 100 万行数据进行加权集成拟合,我们大幅提高了处理 5 - 30 GB 大规模数据集时的运行时性能,在保持相同质量的同时,执行速度也快得多。我们还将默认加权集成迭代次数从 100 次调整为 25 次,这将使所有加权集成的拟合时间加快 4 倍。我们对 fit_pseudolabel 逻辑进行了大量重构,现在应该能获得显著更强的结果。
修复和改进
修复
predictor.fit_weighted_ensemble(refit_full=True)中的返回值。 @Innixma (#1956)修复 LightGBM、CatBoost 和 XGBoost 在 HPO 期间进行内存检查时的崩溃问题。 @Innixma (#3931)
LightGBM 版本升级。 @mglowacki100, @Innixma (#3427)
修复 Ray 未初始化时跳过内存安全子拟合的问题。 @LennartPurucker (#3868)
日志记录改进。 @AnirudhDagar (#3873)
文档和 CI
添加自动基准测试报告生成。 @prateekdesai04 (#4038, #4039)
修复挂起的表格单元测试。 @prateekdesai04 (#4031)
添加 CI 运行之间的包版本比较 @prateekdesai04 (#3962, #3968, #3972)
更新 conf.py 以反映当前年份。 @dassaswat (#3932)
避免重复的单元测试运行。 @prateekdesai04 (#3942)
修复 colab notebook 链接 @prateekdesai04 (#3926)
v1.0.0
版本 1.0.0
今天终于来了……AutoGluon 1.0 已经到来!!经过四年多的开发以及111 位贡献者的 2061 次提交,我们很高兴与大家分享我们努力的成果,创建并普及了世界上最强大、易于使用且功能丰富的自动化机器学习系统。AutoGluon 1.0 带来了预测质量的革命性增强,这得益于多项新的集成创新组合,亮点如下。除了性能增强之外,还进行了许多其他改进,这些改进在各个模块部分中有详细介绍。
注意:不支持加载在旧版本 AutoGluon 上训练的模型。请使用 AutoGluon 1.0 重新训练模型。
本版本支持 Python 3.8, 3.9, 3.10 和 3.11 版本。
本版本包含来自 17 位贡献者的 223 次提交!
完整贡献者列表(按提交数量排序)
@shchur, @zhiqiangdon, @Innixma, @prateekdesai04, @FANGAreNotGnu, @yinweisu, @taoyang1122, @LennartPurucker, @Harry-zzh, @AnirudhDagar, @jaheba, @gradientsky, @melopeo, @ddelange, @tonyhoo, @canerturkmen, @suzhoum
加入社区:
获取最新动态:
聚焦
表格性能增强
AutoGluon 1.0 带来了预测质量的重大增强,在表格建模领域建立了新的最先进水平。据我们所知,AutoGluon 1.0 标志着自 2020 年 3 月原始 AutoGluon 论文发表以来,表格数据最先进水平的最大飞跃。这些增强主要来自两个特性:动态堆叠以减轻堆叠过拟合,以及通过 Zeroshot-HPO 获得的新学习模型超参数组合,该组合来自最新发布的 TabRepo 集成模拟库。总的来说,与 AutoGluon 0.8 相比,它们带来了 75% 的胜率,同时具有更快的推理速度、更低的磁盘使用量和更高的稳定性。
AutoML 基准测试结果
OpenML 于 2023 年 11 月 16 日发布了官方 2023 AutoML 基准测试结果。他们的结果显示 AutoGluon 0.8 在各种任务中是 AutoML 系统中最先进的:“总体而言,在模型性能方面,AutoGluon 在我们的基准测试中始终具有最高的平均排名。” 我们现在展示 AutoGluon 1.0 即使与 AutoGluon 0.8 相比也能取得更优越的结果!
以下是关于 OpenML AutoML 基准测试在 1040 个任务上的比较。LightGBM、XGBoost 和 CatBoost 的结果是通过 AutoGluon 获得的,其他方法则来自官方 2023 AutoML 基准测试结果。AutoGluon 1.0 对传统表格模型具有 95%+ 的胜率,其中包括对 LightGBM 的 99% 胜率和对 XGBoost 的 100% 胜率。AutoGluon 1.0 对其他 AutoML 系统具有 82% 到 94% 的胜率。对于所有方法,AutoGluon 都能够实现 >10% 的平均损失改进(例如:从 90% 准确率提升到 91% 准确率,损失改进为 10%)。AutoGluon 1.0 在 63% 的任务中获得第一名,lightautoml 以 12% 排名第二(AutoGluon 0.8 之前获得第一名的比例为 48%)。AutoGluon 1.0 甚至比 AutoGluon 0.8 平均损失改进了 7.4%!
方法 |
AG 胜率 |
AG 损失改进 |
重新缩放损失 |
排名 |
冠军 |
|---|---|---|---|---|---|
AutoGluon 1.0 (最佳, 4h8c) |
- |
- |
0.04 |
1.95 |
63% |
lightautoml (2023, 4h8c) |
84% |
12.0% |
0.2 |
4.78 |
12% |
H2OAutoML (2023, 4h8c) |
94% |
10.8% |
0.17 |
4.98 |
1% |
FLAML (2023, 4h8c) |
86% |
16.7% |
0.23 |
5.29 |
5% |
MLJAR (2023, 4h8c) |
82% |
23.0% |
0.33 |
5.53 |
6% |
autosklearn (2023, 4h8c) |
91% |
12.5% |
0.22 |
6.07 |
4% |
GAMA (2023, 4h8c) |
86% |
15.4% |
0.28 |
6.13 |
5% |
CatBoost (2023, 4h8c) |
95% |
18.2% |
0.28 |
6.89 |
3% |
TPOT (2023, 4h8c) |
91% |
23.1% |
0.4 |
8.15 |
1% |
LightGBM (2023, 4h8c) |
99% |
23.6% |
0.4 |
8.95 |
0% |
XGBoost (2023, 4h8c) |
100% |
24.1% |
0.43 |
9.5 |
0% |
RandomForest (2023, 4h8c) |
97% |
25.1% |
0.53 |
9.78 |
1% |
AutoGluon 1.0 不仅更准确,而且由于在低内存训练期间新使用了 Ray 子进程,也更加稳定,在 AutoML 基准测试中实现了 0 次任务失败。
AutoGluon 1.0 能够实现所有 AutoML 系统中最快的推理吞吐量,同时仍获得最先进的结果。通过指定 infer_limit fit 参数,用户可以在准确性和推理速度之间进行权衡,以满足他们的需求。
如下图所示,AutoGluon 1.0 为质量和推理吞吐量设定了帕累托前沿,与其他所有 AutoML 系统相比,实现了帕累托优势。AutoGluon 1.0 High 性能优于 AutoGluon 0.8 Best,推理速度快 8 倍,磁盘使用量少 8 倍!
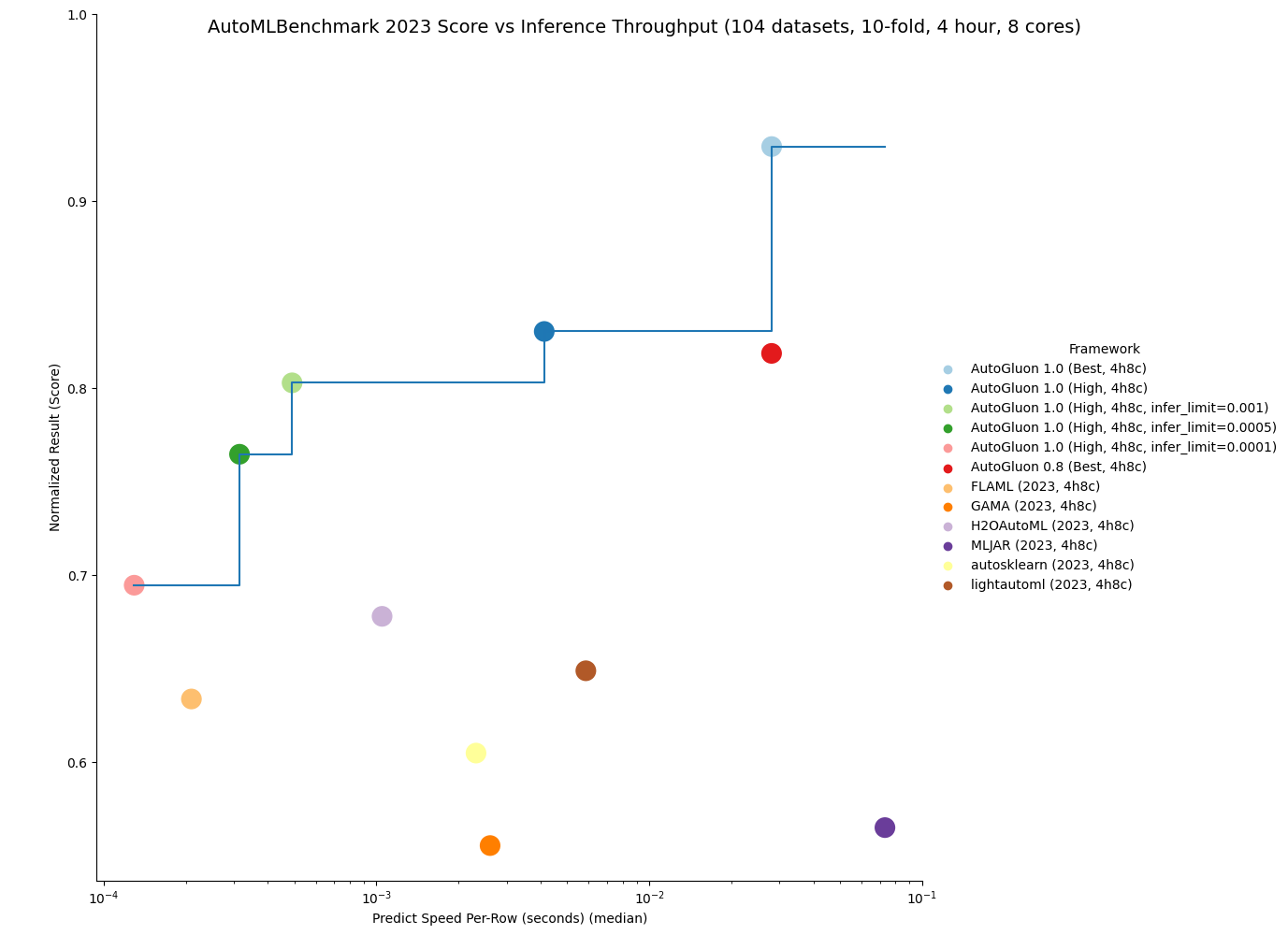
您可以在此处获取更多结果详情。
我们很高兴看到用户能通过 AutoGluon 1.0 增强的性能实现什么成果。一如既往,我们将在未来的版本中继续改进 AutoGluon,为所有人推动 AutoML 的边界。
AutoGluon 多模态 (AutoMM) 亮点图解

AutoMM 的独特性
AutoGluon 多模态 (AutoMM) 将自身与其他开源 AutoML 工具箱区分开来,例如 AutosSklearn、LightAutoML、H2OAutoML、FLAML、MLJAR、TPOT 和 GAMA,这些工具主要专注于表格数据的分类或回归。AutoMM 旨在对跨多种模态(图像、文本、表格和文档,可单独或组合使用)的基础模型进行微调。它为分类、回归、对象检测、命名实体识别、语义匹配和图像分割等任务提供了广泛的功能。相比之下,其他 AutoML 系统通常对图像或文本的支持有限,通常只使用少数预训练模型(如 EfficientNet)或手工设计的规则(如 词袋模型)作为特征提取器。它们通常依赖于传统模型或简单的神经网络。AutoMM 提供了一种独特且全面的 AutoML 方法,是唯一支持灵活多模态和广泛任务的 AutoML 系统。下表详细比较了对各种数据模态、任务和模型类型的支持情况。
数据 |
任务 |
模型 |
||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
图像 |
文本 |
表格 |
文档 |
任意组合 |
分类 |
回归 |
对象检测 |
语义匹配 |
命名实体识别 |
图像分割 |
传统模型 |
深度学习模型 |
基础模型 |
|
LightAutoML |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
|||||||
H2OAutoML |
✓ |
✓ |
✓ |
✓ |
||||||||||
FLAML |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
|||||||
MLJAR |
✓ |
✓ |
✓ |
✓ |
||||||||||
AutoSklearn |
✓ |
✓ |
✓ |
✓ |
✓ |
|||||||||
GAMA |
✓ |
✓ |
✓ |
✓ |
||||||||||
TPOT |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
||||||||
AutoMM |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
特别感谢
我们想通过感谢 Pieter Gijsbers, Sébastien Poirier, Erin LeDell, Joaquin Vanschoren 以及其他 AutoML 基准测试作者来结束本次亮点介绍,感谢他们在提供共享和广泛的基准测试以监控 AutoML 领域进展方面发挥的关键作用。他们的支持对 AutoGluon 项目的持续增长至关重要。
我们还要感谢 Frank Hutter,他持续在 AutoML 领域保持领导地位,组织了 2022 年和 2023 年的 AutoML 会议,将社区聚集在一起分享想法并达成引人入胜的愿景。
最后,我们要感谢 Alex Smola 和 Mu Li 在 Amazon 倡导开源软件,使这个项目成为可能。
额外特别鸣谢
特别感谢 @LennartPurucker 领导了动态堆叠的开发
特别感谢 @ddelange 帮助添加了 Python 3.11 支持
特别感谢 @mglowacki100 提供了许多反馈和建议
特别感谢 @Harry-zzh 贡献了新的语义分割问题类型
一般
亮点
其他增强功能
依赖项更新
将 torch 升级到
>=2.0,<2.2@zhiqiangdon @yinweisu @shchur (#3404, #3587, #3588)将 numpy 升级到
>=1.21,<1.29@prateekdesai04 (#3709)将 scikit-learn 升级到
>=1.3,<1.5@yinweisu @tonyhoo @shchur (#3498)将 scipy 升级到
>=1.5.4,<1.13@prateekdesai04 (#3709)将 LightGBM 升级到
>=3.3,<4.2@mglowacki100 @prateekdesai04 @Innixma (#3427, #3709, #3733)
表格数据
亮点
AutoGluon 1.0 带来了预测质量的重大增强,在表格建模领域建立了新的最先进水平。有关更多详情,请参阅上面的亮点部分!
新功能
添加了
dynamic_stackingpredictor fit 参数以减轻堆叠过拟合 @LennartPurucker @Innixma (#3616)添加了 zeroshot-HPO 学习组合作为
best_quality和high_quality预设的新超参数。 @Innixma @geoalgo (#3750)为 TabularPredictor 添加了实验性 scikit-learn API 兼容封装器。您可以通过
from autogluon.tabular.experimental import TabularClassifier, TabularRegressor访问它们。 @Innixma (#3769)添加了增强型 FT-Transformer @taoyang1122 @Innixma (#3621, #3644, #3692)
添加了
predictor.simulation_artifact()以支持与 TabRepo 的集成 @Innixma (#3555)
性能改进
通过输出裁剪增强了 FastAI 模型在回归上的质量 @LennartPurucker @Innixma (#3597)
添加了跳跃连接加权集成 @LennartPurucker (#3598)
通过使用 ray 进程进行顺序拟合来修复内存泄漏 @LennartPurucker (#3614)
其他增强功能
多层堆叠现在产生确定性结果 @LennartPurucker (#3573)
各种模型依赖项更新 @mglowacki100 (#3373)
Bug 修复 / 代码和文档改进
AutoMM
AutoGluon 多模态 (AutoMM) 旨在仅用三行代码简化基础模型在下游应用中的微调。它与流行的模型库(如 HuggingFace Transformers、TIMM 和 MMDetection)无缝集成,支持广泛的数据模态,包括图像、文本、表格和文档数据,无论单独使用还是组合使用。
新功能
语义分割
引入新的问题类型
semantic_segmentation,用于通过三行代码微调 Segment Anything Model (SAM)。 @Harry-zzh @zhiqiangdon (#3645, #3677, #3697, #3711, #3722, #3728)添加了来自不同领域的全面基准测试,包括自然图像、农业、遥感和医疗健康。
利用参数高效微调 (PEFT) LoRA,在广泛的基准测试中展示了相对于替代方法(VPT、adaptor、BitFit、SAM-adaptor 和 LST)的一致卓越性能。
添加了一个语义分割教程 @zhiqiangdon (#3716)。
默认使用 SAM-ViT Huge(需要 GPU 内存 > 25GB)。
少样本分类
添加了新的
few_shot_classification问题类型,用于训练图像或文本上的少样本分类器。 @zhiqiangdon (#3662, #3681, #3695)利用图像/文本基础模型提取特征并训练 SVM 分类器。
添加了一个少样本分类教程。 @zhiqiangdon (#3662)
支持 torch.compile 以加快训练速度(实验性,需要 torch >=2.2) @zhiqiangdon (#3520)。
性能改进
改进了默认图像骨干网络,在图像基准测试中实现了 100% 的胜率。 @taoyang1122 (#3738)
将 MLP 替换为 FT-Transformer 作为默认表格骨干网络,在文本+表格基准测试中实现了 67% 的胜率。 @taoyang1122 (#3732)
同时使用改进的默认图像骨干网络和 FT-Transformer 在文本+表格+图像基准测试中实现了 62% 的胜率。 @taoyang1122 (#3732, #3738)
稳定性增强
启用了严格的多 GPU CI 测试。 @prateekdesai04 (#3566)
修复了多 GPU 问题。 @FANGAreNotGnu (#3617 #3665 #3684 #3691, #3639, #3618)
可用性增强
支持自定义评估指标,允许定义自定义指标对象并将其传递给
eval_metric参数。 @taoyang1122 (#3548)支持在 notebook 中进行多 GPU 训练(实验性)。 @zhiqiangdon (#3484)
改进了包含系统信息的日志记录。 @zhiqiangdon (#3735)
可扩展性改进
新学习器类设计的引入促进了 AutoMM 中对新任务和数据模态更轻松的支持,增强了整体可扩展性。 @zhiqiangdon (#3650, #3685, #3735)
其他增强功能
添加了选项
hf_text.use_fast用于在hf_text模型中自定义快速分词器的使用。 @zhiqiangdon (#3379)添加了回退评估/验证指标,支持
f1_macrof1_micro和f1_weighted。 @FANGAreNotGnu (#3696)支持使用 DDP 策略进行多 GPU 推理。 @zhiqiangdon (#3445, #3451)
将 torch 升级到 2.0。 @zhiqiangdon (#3404)
将 lightning 升级到 2.0 @zhiqiangdon (#3419)
将 torchmetrics 升级到 1.0 @zhiqiangdon (#3422)
代码改进
使用学习器类重构了 AutoMM,以改进设计。 @zhiqiangdon (#3650, #3685, #3735)
重构了 FT-Transformer。 @taoyang1122 (#3621, #3700)
重构了对象检测、语义分割和 NER 的可视化工具。 @zhiqiangdon (#3716)
其他代码重构/清理: @zhiqiangdon @FANGAreNotGnu (#3383 #3399 #3434 #3667 #3684 #3695)
Bug 修复/文档改进
修复了一个 ONNX 导出问题。 @AnirudhDagar (#3725)
改进了 AutoMM 介绍,使其更清晰。 @zhiqiangdon (#3388 #3726)
改进了 AutoMM API 文档。 @zhiqiangdon @AnirudhDagar (#3772 #3777)
其他 bug 修复 @zhiqiangdon @FANGAreNotGnu @taoyang1122 @tonyhoo @rsj123 @AnirudhDagar (#3384, #3424, #3526, #3593, #3615, #3638, #3674, #3693, #3702, #3690, #3729, #3736, #3474, #3456, #3590, #3660)
其他文档改进 @zhiqiangdon @FANGAreNotGnu @taoyang1122 (#3397, #3461, #3579, #3670, #3699, #3710, #3716, #3737, #3744, #3745, #3680)
时间序列
亮点
AutoGluon 1.0 包含了时间序列模块的众多可用性和性能改进。这些改进包括自动处理缺失数据和不规则时间序列、新的预测指标(包括自定义指标支持)、高级时间序列交叉验证选项以及新的预测模型。AutoGluon 在预测准确性方面取得了最先进的结果,与其他流行的预测框架相比,胜率达到 70%+。
新特性
新的预测指标
WAPE,RMSSE,SQL+ 改进的指标文档 @melopeo @shchur (#3747, #3632, #3510, #3490)鲁棒性增强:
TimeSeriesPredictor现在可以处理包含所有 pandas 频率、不规则时间戳或用NaN表示缺失值的数据 @shchur (#3563, #3454)新模型:基于共形预测的间歇性需求预测模型(
ADIDA、CrostonClassic、CrostonOptimized、CrostonSBA、IMAPA);来自 GluonTS 的WaveNet和NPTS;新的基线模型(Average、SeasonalAverage、Zero) @canerturkmen @shchur (#3706, #3742, #3606, #3459)高级交叉验证选项:使用
refit_every_n_windows避免为每个验证窗口重新训练模型,或使用val_step_size参数调整验证窗口之间的步长,应用于TimeSeriesPredictor.fit@shchur (#3704, #3537)
增强功能
为深度学习预测模型启用 Ray Tune @canerturkmen (#3705)
静态特征现在可以直接传递给
TimeSeriesDataFrame.from_path和TimeSeriesDataFrame.from_data_frame构造函数 @shchur (#3635)
性能改进
由于新的预设和更新的模型训练时间分配逻辑,在低时间限制下实现了更准确的预测 @shchur (#3749, #3657, #3741)
DirectTabular和RecursiveTabular模型的训练和预测更快 + 内存使用更少 (#3740, #3620, #3559)通过将导入语句移到模型类内部来减少
autogluon.timeseries的导入时间 (#3514)
Bug 修复 / 代码和文档改进
将
TimeSeriesPredictor的 API 与TabularPredictor对齐,删除已弃用的方法 @shchur (#3714, #3655, #3396)通用 bug 修复和改进 @shchur(#3758, #3756, #3755, #3754, #3746, #3743, #3727, #3698, #3654, #3653, #3648, #3628, #3588, #3560, #3558, #3536, #3533, #3523, #3522, #3476, #3463)
EDA
EDA 模块将在稍后发布,因为在准备好发布 1.0 版本之前还需要额外的开发工作。当 EDA 准备好发布时,我们将发布公告。目前,请继续使用 "autogluon.eda==0.8.2"。
已弃用
一般
表格数据
如果使用已弃用的方法,Tabular 将记录警告。计划在 AutoGluon 1.2 中删除已弃用的方法 @Innixma (#3701)
autogluon.tabular.TabularPredictorpredictor.get_model_names()->predictor.model_names()predictor.get_model_names_persisted()->predictor.model_names(persisted=True)predictor.compile_models()->predictor.compile()predictor.persist_models()->predictor.persist()predictor.unpersist_models()->predictor.unpersist()predictor.get_model_best()->predictor.model_bestpredictor.get_pred_from_proba()->predictor.predict_from_proba()predictor.get_oof_pred_proba()->predictor.predict_proba_oof()predictor.get_oof_pred()->predictor.predict_oof()predictor.get_model_full_dict()->predictor.model_refit_map()predictor.get_size_disk()->predictor.disk_usage()predictor.get_size_disk_per_file()->predictor.disk_usage_per_file()predictor.leaderboard()的silent参数已弃用,替换为display,默认为 False同样适用于
predictor.evaluate()和predictor.evaluate_predictions()
AutoMM
已弃用
FewShotSVMPredictor,转而使用新的few_shot_classification问题类型 @zhiqiangdon (#3699)已弃用
AutoMMPredictor,转而使用MultiModalPredictor@zhiqiangdon (#3650)autogluon.multimodal.MultiModalPredictor已弃用 fit API 中的
config参数。 @zhiqiangdon (#3679)已弃用 init API 中的
init_scratch和pipeline参数 @zhiqiangdon (#3668)
时间序列
autogluon.timeseries.TimeSeriesPredictor已弃用参数
TimeSeriesPredictor(ignore_time_index: bool)。现在,如果数据包含不规则时间戳,可以使用data = data.convert_frequency(freq)将其转换为规则频率,或者在创建预测器时提供频率,例如TimeSeriesPredictor(freq=freq)。predictor.evaluate()现在返回一个字典(以前返回浮点数)predictor.score()->predictor.evaluate()predictor.get_model_names()->predictor.model_names()predictor.get_model_best()->predictor.model_best指标
"mean_wQuantileLoss"已更名为"WQL"predictor.leaderboard()的silent参数已弃用,替换为display,默认为 False在
predictor.fit()中将hyperparameters设置为字符串时,支持的值现在是"default"、"light"和"very_light"
autogluon.timeseries.TimeSeriesDataFramedf.to_regular_index()->df.convert_frequency()已弃用方法
df.get_reindexed_view()。有关如何处理不规则时间戳的信息,请参阅上面TimeSeriesPredictor下ignore_time_index的弃用说明。
模型
所有基于 MXNet 的模型(
DeepARMXNet、MQCNNMXNet、MQRNNMXNet、SimpleFeedForwardMXNet、TemporalFusionTransformerMXNet、TransformerMXNet)均已移除Statmodels 中的统计模型(
ARIMA、Theta、ETS)已被 StatsForecast 中的对应模型取代(#3513)。请注意,这些模型现在的超参数名称不同。DirectTabular现在使用mlforecast后端实现(与RecursiveTabular相同),模型的多数超参数名称已更改。
autogluon.timeseries.TimeSeriesEvaluator已弃用。请改用autogluon.timeseries.metrics中提供的指标。autogluon.timeseries.splitter.MultiWindowSplitter和autogluon.timeseries.splitter.LastWindowSplitter已弃用。请改用TimeSeriesPredictor.fit的num_val_windows和val_step_size参数(或者,使用autogluon.timeseries.splitter.ExpandingWindowSplitter)。
论文
AutoGluon-TimeSeries:用于概率时间序列预测的 AutoML
我们在 2023 年 AutoML 会议上发表了一篇关于 AutoGluon-TimeSeries 的论文(论文链接,YouTube 视频)。在论文中,我们对 AutoGluon 和流行的开源预测框架(包括 DeepAR、TFT、AutoARIMA、AutoETS、AutoPyTorch)进行了基准测试。AutoGluon 在点预测和概率预测方面取得了 SOTA 结果,甚至对事后看来最佳的模型组合也达到了 65% 的胜率。
TabRepo:表格模型评估的大规模仓库及其 AutoML 应用
我们在 arXiv 上发表了一篇关于表格 Zeroshot-HPO 集成模拟的论文(论文链接,GitHub)。这篇论文是实现 AutoGluon 1.0 性能改进的关键,我们计划继续开发代码库以支持未来的增强功能。
XTab:表格 Transformer 的跨表预训练
我们在 ICML 2023 发表了一篇关于表格 Transformer 预训练的论文(论文链接,GitHub)。在论文中,我们展示了表格深度学习模型的最新性能,包括能够媲美 XGBoost 和 LightGBM 模型的性能。尽管预训练的 Transformer 尚未集成到 AutoGluon 中,但我们计划在未来的版本中集成它。
在特征空间中学习多模态数据增强
我们关于学习多模态数据增强的论文已被 ICLR 2023 接受(论文链接,GitHub)。这篇论文引入了一个即插即用模块,用于在特征空间中学习多模态数据增强,对模态的身份或模态之间的关系没有任何约束。我们展示了它可以 (1) 提高多模态深度学习架构的性能,(2) 应用于以前未考虑过的模态组合,以及 (3) 在包含图像、文本和表格数据的各种应用中取得最新成果。这项工作尚未集成到 AutoGluon 中,但我们计划在未来的版本中集成它。
通过可控扩散模型进行目标检测数据增强
我们关于生成式目标检测数据增强的论文已被 WACV 2024 接受(论文和 GitHub 链接即将提供)。这篇论文提出了一种基于可控扩散模型和 CLIP 的数据增强流程,通过视觉先验生成来引导生成,并使用类别校准的 CLIP 分数进行后过滤以控制其质量。我们证明,在使用我们的增强流程与不同检测器时,各种任务和设置的性能都得到了提升。尽管扩散模型目前尚未集成到 AutoGluon 中,但我们计划在未来的版本中集成这些数据增强技术。
调整图像基础模型以进行视频理解
我们在 ICLR 2023 发表了一篇关于如何高效地调整图像基础模型以进行视频理解的论文(论文链接,GitHub)。这篇论文引入了空间适应、时间适应和联合适应,以逐步为冻结的图像模型配备时空推理能力。所提出的方法在训练成本方面大大节省了大型基础模型,同时取得了与传统完全微调相当甚至更好的性能。
v0.8.3
版本 0.8.3
v0.8.3 是一个补丁版本,用于解决安全漏洞。
在此处查看完整的提交更改日志:https://github.com/autogluon/autogluon/compare/v0.8.2…v0.8.3
此版本支持 Python 3.8、3.9 和 3.10 版本。
更改
v0.8.2
版本 0.8.2
v0.8.2 是一个热修复版本,用于固定 pydantic 版本,以避免在 HPO 期间崩溃。
与往常一样,只能使用原始训练模型所使用的 AutoGluon 版本加载之前训练的模型。不支持加载在不同版本的 AutoGluon 中训练的模型。
在此处查看完整的提交更改日志:https://github.com/autogluon/autogluon/compare/v0.8.1…v0.8.2
此版本支持 Python 3.8、3.9 和 3.10 版本。
更改
codespell:action、config + 一些拼写错误已修复 @yarikoptic @yinweisu (#3323)
取消固定
sentencepiece@zhiqiangdon (#3368)固定
pydantic@yinweisu (3370)
v0.8.1
版本 0.8.1
v0.8.1 是一个错误修复版本。
与往常一样,只能使用原始训练模型所使用的 AutoGluon 版本加载之前训练的模型。不支持加载在不同版本的 AutoGluon 中训练的模型。
在此处查看完整的提交更改日志:https://github.com/autogluon/autogluon/compare/v0.8.0…v0.8.1
此版本支持 Python 3.8、3.9 和 3.10 版本。
更改
文档改进
错误修复 / 通用改进
将 PyMuPDF 移至可选 @Innixma @zhiqiangdon (#3331)
移除 fairscale @zhiqiangdon (#3342)
修复
DirectTabular模型在某些指标上失败;隐藏AutoARIMA生成的警告 @shchur (#3350)降低 AutoMM high_quality_hpo 的每 GPU 批处理大小,以避免某些极端情况下的内存不足错误 @zhiqiangdon (#3360)
v0.8.0
版本 0.8.0
我们很高兴地宣布 AutoGluon 0.8 版本发布。
注意:不支持加载在不同版本的 AutoGluon 中训练的模型。
此版本包含了来自 20 位贡献者的 196 次提交!
在此处查看完整的提交更改日志:https://github.com/autogluon/autogluon/compare/0.7.0…0.8.0
特别感谢 @geoalgo 在生成此版本中实验性的表格 Zeroshot-HPO 组合方面的合作!
完整贡献者列表(按提交数量排序)
@shchur, @Innixma, @yinweisu, @gradientsky, @FANGAreNotGnu, @zhiqiangdon, @gidler, @liangfu, @tonyhoo, @cheungdaven, @cnpgs, @giswqs, @suzhoum, @yongxinw, @isunli, @jjaeyeon, @xiaochenbin9527, @yzhliu, @jsharpna, @sxjscience
AutoGluon 0.8 支持 Python 3.8、3.9 和 3.10 版本。
更改
亮点
AutoGluon TimeSeries 引入了几项重大改进,包括新模型、提升预测准确性的升级预设,以及加速训练和推理的优化。
AutoGluon Tabular 现在支持**在二元分类中校准决策阈值**(API),这大大改善了像
f1和balanced_accuracy等指标。例如,f1分数从0.70提高到0.73并不罕见。我们**强烈**鼓励所有使用这些指标的用户尝试新的决策阈值校准逻辑。AutoGluon MultiModal 引入了两项新功能:1)**PDF 文档分类**,以及 2)**开放词汇目标检测**。
AutoGluon MultiModal 升级了目标检测的预设,现在提供
medium_quality、high_quality和best_quality选项。实证结果表明,使用相同的预设,mAP(平均精度均值)指标相对提高了约 20%。AutoGluon Tabular 添加了实验性的 **Zeroshot HPO 配置**,该配置在行数小于 10000 的小型数据集上表现良好,前提是提供至少一小时的训练时间(相对于
best_quality胜率约为 60%)。要尝试此功能,在调用fit()时指定presets="experimental_zeroshot_hpo_hybrid"。AutoGluon EDA 添加了对**异常检测**和**偏依赖图**的支持。
AutoGluon Tabular 已添加对 **TabPFN** 的实验性支持,TabPFN 是一种预训练的表格 Transformer 模型。通过
pip install autogluon.tabular[all,tabpfn]进行尝试(超参数键为“TABPFN”)!
一般
通用文档改进 @tonyhoo @Innixma @yinweisu @gidler @cnpgs @isunli @giswqs (#2940, #2953, #2963, #3007, #3027, #3059, #3068, #3083, #3128, #3129, #3130, #3147, #3174, #3187, #3256, #3258, #3280, #3306, #3307, #3311, #3313)
通用代码修复和改进 @yinweisu @Innixma (#2921, #3078, #3113, #3140, #3206)
CI 改进 @yinweisu @gidler @yzhliu @liangfu @gradientsky (#2965, #3008, #3013, #3020, #3046, #3053, #3108, #3135, #3159, #3283, #3185)
更新命名空间包以实现 PEP420 兼容性 @gradientsky (#3228)
多模态
AutoGluon MultiModal(也称为 AutoMM)引入了两项新功能:1)PDF 文档分类,以及 2)开放词汇目标检测。此外,我们升级了目标检测的预设,现在提供 medium_quality、high_quality 和 best_quality 选项。实证结果表明,使用相同的预设,mAP(平均精度均值)指标相对提高了约 20%。
新功能
PDF 文档分类。查看 教程 @cheungdaven (#2864, #3043)
开放词汇目标检测。查看 教程 @FANGAreNotGnu (#3164)
性能改进
将检测引擎从 mmdet 2.x 升级到 mmdet 3.x,并升级我们的预设 @FANGAreNotGnu (#3262)
medium_quality: yolo-s -> yolox-lhigh_quality: yolox-l -> DINO-Res50best_quality: yolox-x -> DINO-Swin_l
启用检测骨干网络冻结,以提高微调速度并节省 GPU 使用量 @FANGAreNotGnu (#3220)
其他增强功能
支持将数据路径传递给 fit() API @zhiqiangdon (#3006)
将 TIMM 升级到最新 v0.9.* @zhiqiangdon (#3282)
支持目标检测的 xywh 输出 @FANGAreNotGnu (#2948)
支持定制高级图像数据增强。用户可以将 torchvision transform 对象列表作为图像增强传递。 @zhiqiangdon (#3022)
添加 yoloxm 和 yoloxtiny @FangAreNotGnu (#3038)
添加用于目标检测的 MultiImageMix 数据集 @FangAreNotGnu (#3094)
支持加载特定检查点。用户可以加载除 model.ckpt 和 last.ckpt 之外的中间检查点。@zhiqiangdon (#3244)
添加一些用于模型统计的预测器属性 @zhiqiangdon (#3289)
trainable_parameters返回可训练参数的数量。total_parameters返回总参数数量。model_size返回以兆字节为单位的模型大小。
Bug 修复 / 代码和文档改进
通用错误修复和改进 @zhiqiangdon @liangfu @cheungdaven @xiaochenbin9527 @Innixma @FANGAreNotGnu @gradientsky @yinweisu @yongxinw (#2939, #2989, #2983, #2998, #3001, #3004, #3006, #3025, #3026, #3048, #3055, #3064, #3070, #3081, #3090, #3103, #3106, #3119, #3155, #3158, #3167, #3180, #3188, #3222, #3261, #3266, #3277, #3279, #3261, #3267)
重构推断问题类型和输出形状的代码 @zhiqiangdon (#3227)
在训练期间记录 GPU 信息,包括 GPU 总内存、可用内存、GPU 卡名称和 CUDA 版本 @zhiqaingdon (#3291)
表格数据
新功能
添加了
calibrate_decision_threshold(教程),它允许优化给定指标的决策阈值以显着提高指标分数。@Innixma (#3298)我们添加了一个实验性的 Zeroshot HPO 配置,当提供至少一小时的训练时间时,该配置在行数小于 10000 的小型数据集上表现良好。要尝试此功能,在调用
fit()时指定presets="experimental_zeroshot_hpo_hybrid"@Innixma @geoalgo (#3312)TabPFN 模型现在作为实验模型受到支持。当推理速度不是问题且训练数据行数小于 10,000 时,TabPFN 是一个可行的模型选项。通过
pip install autogluon.tabular[all,tabpfn]尝试一下!(超参数键是“TABPFN”)! @Innixma (#3270)对分布式训练的后端支持,这将随下一个 Cloud 模块版本一起提供。@yinweisu (#3054, #3110, #3115, #3131, #3142, #3179, #3216)
性能改进
其他增强功能
Bug 修复 / 代码和文档改进
跨操作系统加载已 fit 的 TabularPredictor 现在应该能正常工作 @yinweisu @Innixma
通用错误修复和改进 @Innixma @cnpgs @shchur @yinweisu @gradientsky (#2865, #2936, #2990, #3045, #3060, #3069, #3148, #3182, #3199, #3226, #3257, #3259, #3268, #3269, #3287, #3288, #3285, #3293, #3294, #3302)
时间序列
在 v0.8 版本中,我们对 Time Series 模块引入了几项重大改进,包括新模型、提升预测准确性的升级预设,以及加速训练和推理的优化。
亮点
新模型:来自 GluonTS 的
PatchTST和DLinear,以及基于与mlforecast库集成的RecursiveTabular@shchur (#3177, #3184, #3230)AutoARIMA、AutoETS、Theta、DirectTabular、WeightedEnsemble模型的训练和推理速度提高了 3-6 倍 @shchur (#3062, #3214, #3252)
新功能
由于预测缓存,重复调用
predict()、leaderboard()和evaluate()的速度大大加快 @shchur (#3237)使用
fit()的num_val_windows参数,通过使用多个验证窗口来减少过拟合 @shchur (#3080)使用
fit()的excluded_model_types参数,从预设中排除某些模型 @shchur (#3231)
增强功能
DirectTabular模型(以前称为AutoGluonTabular)的改进:更快的特征化,如果eval_metric设置为"mean_wQuantileLoss",则训练为分位数回归模型 @shchur (#2973, #3211)
次要改进 / 文档 / 错误修复
探索性数据分析 (EDA) 工具
在 0.8 版本中,我们引入了一些新工具,帮助进行数据探索和特征工程。
**异常检测** @gradientsky (#3124, #3137) - 有助于识别数据中显著偏离常规的异常模式或行为。它最适用于查找异常值、罕见事件或可疑活动,这些可能预示着欺诈、缺陷或系统故障。查看 异常检测教程 以探索此功能。
**偏依赖图** @gradientsky (#3071, #3079) - 可视化特征与模型输出之间对于数据集中每个独立实例的关系。双向变体可以可视化任意两个特征之间的潜在交互。详情请参阅此教程:使用交互图了解数据信息
Bug 修复 / 代码和文档改进
将
quick_fit中的回归分析切换为使用残差图 @gradientsky (#3039)向
autogluon.eda.auto添加了explain_rows方法 - Kernel SHAP 可视化 @gradientsky (#3014)