用于语义分割的 AutoMM - 快速入门¶
![]()

语义分割是一种计算机视觉任务,其目标是创建图像的详细像素级分割图,将每个像素分配给特定的类别或对象。这项技术在各种应用中至关重要,例如在自动驾驶汽车中用于识别车辆、行人、交通标志、路面和其他道路特征。
Segment Anything Model (SAM) 是一个基础模型,在包含 10 亿个掩码和 1100 万张图像的庞大数据集上进行了预训练。虽然 SAM 在通用场景下表现出色,但在应用于遥感、医学影像、农业和制造业等专业领域时会遇到挑战。幸运的是,AutoMM 通过简化 SAM 在特定领域数据上的微调来解决这个问题。
在这个易于遵循的教程中,我们将指导您如何使用 AutoMM 微调 SAM。只需调用一次 fit() API,您就可以轻松训练模型。
准备数据¶
为了演示目的,我们使用 Kaggle 上的叶片病害分割数据集。这个数据集是实现植物病害自动化检测的一个很好的例子,特别是对于加速植物病理学过程而言。分割叶片或植物上的特定区域可能非常具有挑战性,尤其是在处理较小的病害区域或各种类型的病害时。
首先,下载并准备数据集。
download_dir = './ag_automm_tutorial'
zip_file = 'https://automl-mm-bench.s3.amazonaws.com/semantic_segmentation/leaf_disease_segmentation.zip'
from autogluon.core.utils.loaders import load_zip
load_zip.unzip(zip_file, unzip_dir=download_dir)
Downloading ./ag_automm_tutorial/file.zip from https://automl-mm-bench.s3.amazonaws.com/semantic_segmentation/leaf_disease_segmentation.zip...
0%| | 0.00/53.3M [00:00<?, ?iB/s]
16%|█▌ | 8.38M/53.3M [00:00<00:01, 36.2MiB/s]
31%|███▏ | 16.8M/53.3M [00:00<00:00, 41.1MiB/s]
44%|████▍ | 23.4M/53.3M [00:00<00:00, 42.1MiB/s]
52%|█████▏ | 27.6M/53.3M [00:00<00:00, 32.8MiB/s]
63%|██████▎ | 33.5M/53.3M [00:00<00:00, 32.1MiB/s]
75%|███████▌ | 40.2M/53.3M [00:01<00:00, 25.9MiB/s]
81%|████████ | 43.0M/53.3M [00:01<00:00, 23.4MiB/s]
94%|█████████▍| 50.3M/53.3M [00:01<00:00, 31.3MiB/s]
100%|██████████| 53.3M/53.3M [00:01<00:00, 30.1MiB/s]
接下来,加载 CSV 文件,确保相对路径被展开,以便在训练和测试期间正确加载数据。
import pandas as pd
import os
dataset_path = os.path.join(download_dir, 'leaf_disease_segmentation')
train_data = pd.read_csv(f'{dataset_path}/train.csv', index_col=0)
val_data = pd.read_csv(f'{dataset_path}/val.csv', index_col=0)
test_data = pd.read_csv(f'{dataset_path}/test.csv', index_col=0)
image_col = 'image'
label_col = 'label'
def path_expander(path, base_folder):
path_l = path.split(';')
return ';'.join([os.path.abspath(os.path.join(base_folder, path)) for path in path_l])
for per_col in [image_col, label_col]:
train_data[per_col] = train_data[per_col].apply(lambda ele: path_expander(ele, base_folder=dataset_path))
val_data[per_col] = val_data[per_col].apply(lambda ele: path_expander(ele, base_folder=dataset_path))
test_data[per_col] = test_data[per_col].apply(lambda ele: path_expander(ele, base_folder=dataset_path))
print(train_data[image_col].iloc[0])
print(train_data[label_col].iloc[0])
/home/ci/autogluon/docs/tutorials/multimodal/image_segmentation/ag_automm_tutorial/leaf_disease_segmentation/train_images/00002.jpg
/home/ci/autogluon/docs/tutorials/multimodal/image_segmentation/ag_automm_tutorial/leaf_disease_segmentation/train_masks/00002.png
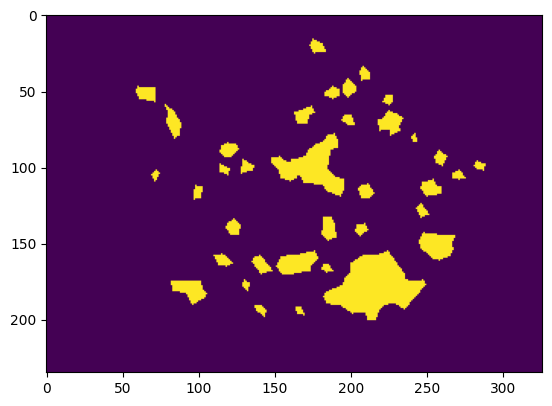
每个 Pandas DataFrame 包含两列:一列用于图像路径,另一列用于相应的地面真相掩码。让我们仔细看看训练数据的 DataFrame。
train_data.head()
| 图像 | 标签 | |
|---|---|---|
| 0 | /home/ci/autogluon/docs/tutorials/multimodal/i... | /home/ci/autogluon/docs/tutorials/multimodal/i... |
| 1 | /home/ci/autogluon/docs/tutorials/multimodal/i... | /home/ci/autogluon/docs/tutorials/multimodal/i... |
| 2 | /home/ci/autogluon/docs/tutorials/multimodal/i... | /home/ci/autogluon/docs/tutorials/multimodal/i... |
| 3 | /home/ci/autogluon/docs/tutorials/multimodal/i... | /home/ci/autogluon/docs/tutorials/multimodal/i... |
| 4 | /home/ci/autogluon/docs/tutorials/multimodal/i... | /home/ci/autogluon/docs/tutorials/multimodal/i... |
我们还可以可视化一张图像及其地面真相掩码。
from autogluon.multimodal.utils import SemanticSegmentationVisualizer
visualizer = SemanticSegmentationVisualizer()
visualizer.plot_image(test_data.iloc[0]['image'])

visualizer.plot_image(test_data.iloc[0]['label'])
零样本评估¶
现在,让我们看看预训练的 SAM 模型分割图像的效果如何。为了演示,我们将使用基础 SAM 模型。
from autogluon.multimodal import MultiModalPredictor
predictor_zero_shot = MultiModalPredictor(
problem_type="semantic_segmentation",
label=label_col,
hyperparameters={
"model.sam.checkpoint_name": "facebook/sam-vit-base",
},
num_classes=1, # forground-background segmentation
)
初始化预测器后,您可以直接执行推理。
pred_zero_shot = predictor_zero_shot.predict({'image': [test_data.iloc[0]['image']]})
INFO: Using default `ModelCheckpoint`. Consider installing `litmodels` package to enable `LitModelCheckpoint` for automatic upload to the Lightning model registry.
visualizer.plot_mask(pred_zero_shot)
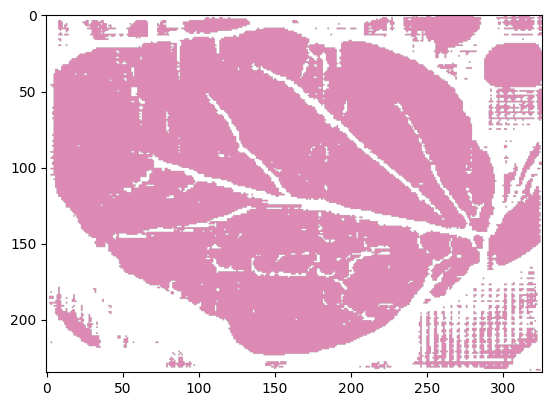
值得注意的是,没有提示的 SAM 输出的是粗略的叶片掩码,而不是病害掩码,因为它缺乏关于领域任务的上下文信息。虽然 SAM 在提供适当的点击提示时可以表现更好,但对于某些需要独立模型进行部署的应用来说,它可能不是一个理想的端到端解决方案。
您还可以在测试数据上进行零样本评估。
scores = predictor_zero_shot.evaluate(test_data, metrics=["iou"])
print(scores)
{'iou': 0.1398000568151474}
INFO: Using default `ModelCheckpoint`. Consider installing `litmodels` package to enable `LitModelCheckpoint` for automatic upload to the Lightning model registry.
正如预期的那样,零样本 SAM 的测试分数相对较低。接下来,我们将探讨如何微调 SAM 以提高性能。
微调 SAM¶
初始化一个新的预测器,并使用训练和验证数据对其进行拟合。
from autogluon.multimodal import MultiModalPredictor
import uuid
save_path = f"./tmp/{uuid.uuid4().hex}-automm_semantic_seg"
predictor = MultiModalPredictor(
problem_type="semantic_segmentation",
label="label",
hyperparameters={
"model.sam.checkpoint_name": "facebook/sam-vit-base",
},
path=save_path,
)
predictor.fit(
train_data=train_data,
tuning_data=val_data,
time_limit=180, # seconds
)
=================== System Info ===================
AutoGluon Version: 1.3.1b20250508
Python Version: 3.11.9
Operating System: Linux
Platform Machine: x86_64
Platform Version: #1 SMP Wed Mar 12 14:53:59 UTC 2025
CPU Count: 8
Pytorch Version: 2.6.0+cu124
CUDA Version: 12.4
Memory Avail: 26.31 GB / 30.95 GB (85.0%)
Disk Space Avail: 185.21 GB / 255.99 GB (72.3%)
===================================================
AutoMM starts to create your model. ✨✨✨
To track the learning progress, you can open a terminal and launch Tensorboard:
```shell
# Assume you have installed tensorboard
tensorboard --logdir /home/ci/autogluon/docs/tutorials/multimodal/image_segmentation/tmp/3edb560feff3479786681311fd8f7fb8-automm_semantic_seg
```
INFO: Seed set to 0
GPU Count: 1
GPU Count to be Used: 1
INFO: Using 16bit Automatic Mixed Precision (AMP)
INFO: GPU available: True (cuda), used: True
INFO: TPU available: False, using: 0 TPU cores
INFO: HPU available: False, using: 0 HPUs
INFO: `Trainer(val_check_interval=1.0)` was configured so validation will run at the end of the training epoch..
INFO: LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
INFO:
| Name | Type | Params | Mode
-------------------------------------------------------------------------
0 | model | SAMForSemanticSegmentation | 93.4 M | train
1 | validation_metric | Binary_IoU | 0 | train
2 | loss_func | StructureLoss | 0 | train
-------------------------------------------------------------------------
3.6 M Trainable params
89.8 M Non-trainable params
93.4 M Total params
373.703 Total estimated model params size (MB)
17 Modules in train mode
208 Modules in eval mode
/home/ci/opt/venv/lib/python3.11/site-packages/torch/nn/_reduction.py:51: UserWarning: size_average and reduce args will be deprecated, please use reduction='mean' instead.
warnings.warn(warning.format(ret))
INFO: Time limit reached. Elapsed time is 0:03:00. Signaling Trainer to stop.
INFO: Epoch 0, global step 96: 'val_iou' reached 0.55206 (best 0.55206), saving model to '/home/ci/autogluon/docs/tutorials/multimodal/image_segmentation/tmp/3edb560feff3479786681311fd8f7fb8-automm_semantic_seg/epoch=0-step=96.ckpt' as top 3
AutoMM has created your model. 🎉🎉🎉
To load the model, use the code below:
```python
from autogluon.multimodal import MultiModalPredictor
predictor = MultiModalPredictor.load("/home/ci/autogluon/docs/tutorials/multimodal/image_segmentation/tmp/3edb560feff3479786681311fd8f7fb8-automm_semantic_seg")
```
If you are not satisfied with the model, try to increase the training time,
adjust the hyperparameters (https://autogluon.cn/stable/tutorials/multimodal/advanced_topics/customization.html),
or post issues on GitHub (https://github.com/autogluon/autogluon/issues).
<autogluon.multimodal.predictor.MultiModalPredictor at 0x7f9867de4810>
在底层实现中,我们使用 LoRA 进行高效微调。请注意,在不进行超参数自定义的情况下,庞大的 SAM 模型是默认模型,在许多情况下需要进行高效微调。
微调后,在测试数据上评估 SAM 模型。
scores = predictor.evaluate(test_data, metrics=["iou"])
print(scores)
{'iou': 0.5086008906364441}
INFO: Using default `ModelCheckpoint`. Consider installing `litmodels` package to enable `LitModelCheckpoint` for automatic upload to the Lightning model registry.
得益于微调过程,测试分数显著提高。
为了可视化效果,让我们检查微调后的预测掩码。
pred = predictor.predict({'image': [test_data.iloc[0]['image']]})
INFO: Using default `ModelCheckpoint`. Consider installing `litmodels` package to enable `LitModelCheckpoint` for automatic upload to the Lightning model registry.
visualizer.plot_mask(pred)
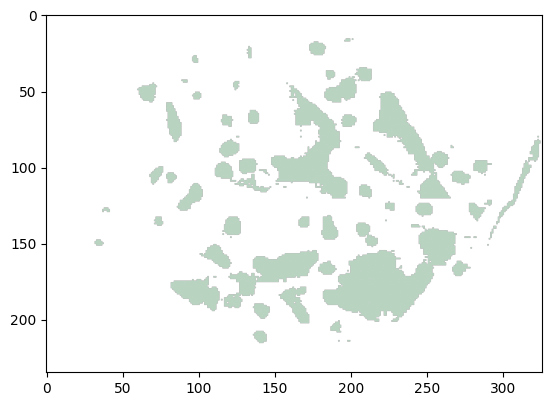
从结果中可以看出,预测掩码现在与地面真相更加接近。这证明了使用 AutoMM 微调 SAM 用于特定领域应用的有效性,增强了其在叶片病害分割等任务中的性能。
保存和加载¶
训练好的预测器在 fit() 结束时会自动保存,您可以轻松重新加载它。
警告
MultiModalPredictor.load() 隐式使用了 pickle 模块,该模块已知不安全。可以构造恶意的 pickle 数据,在反序列化过程中执行任意代码。切勿加载可能来自不受信任来源或可能已被篡改的数据。只加载您信任的数据。
loaded_predictor = MultiModalPredictor.load(save_path)
scores = loaded_predictor.evaluate(test_data, metrics=["iou"])
print(scores)
Load pretrained checkpoint: /home/ci/autogluon/docs/tutorials/multimodal/image_segmentation/tmp/3edb560feff3479786681311fd8f7fb8-automm_semantic_seg/model.ckpt
INFO: Using default `ModelCheckpoint`. Consider installing `litmodels` package to enable `LitModelCheckpoint` for automatic upload to the Lightning model registry.
{'iou': 0.5086008906364441}
我们可以看到评估分数与之前相同,这意味着模型是同一个!
其他示例¶
您可以访问AutoMM 示例,探索 AutoMM 的其他示例。
自定义¶
要了解如何自定义 AutoMM,请参阅自定义 AutoMM。