版本 1.0.0¶
今天终于到来了……AutoGluon 1.0 已发布!经过四年多的开发和111 位贡献者的 2061 次提交,我们很高兴与您分享我们努力创造并普及世界上最强大、易用且功能丰富的自动化机器学习系统的成果。AutoGluon 1.0 带来了预测质量的变革性增强,这得益于多种新颖集成创新的结合,如下所示。除了性能提升之外,还在各个模块部分详细介绍了许多其他改进。
注意:不支持加载在旧版本 AutoGluon 上训练的模型。请使用 AutoGluon 1.0 重新训练模型。
此版本支持 Python 3.8、3.9、3.10 和 3.11 版本。
此版本包含来自 17 位贡献者的 223 次提交!
全部贡献者列表(按提交次数排序)
@shchur, @zhiqiangdon, @Innixma, @prateekdesai04, @FANGAreNotGnu, @yinweisu, @taoyang1122, @LennartPurucker, @Harry-zzh, @AnirudhDagar, @jaheba, @gradientsky, @melopeo, @ddelange, @tonyhoo, @canerturkmen, @suzhoum
加入社区:
获取最新动态:


亮点¶
表格数据性能增强¶
AutoGluon 1.0 提供了预测质量的重大增强,在表格数据建模领域树立了新的标杆。据我们所知,AutoGluon 1.0 是自 2020 年 3 月发布原始 AutoGluon 论文以来,表格数据领域最重大的技术飞跃。这些增强主要来自两个特性:动态堆叠 (Dynamic stacking) 以缓解堆叠过拟合,以及通过 Zeroshot-HPO 获得的新学习到的模型超参数组合 (Learned model hyperparameters portfolio),后者来自新发布的 TabRepo 集成模拟库。总而言之,这些改进使得 AutoGluon 1.0 与 AutoGluon 0.8 相比,胜率提高了 75%,同时推理速度更快,磁盘占用更低,稳定性更高。
AutoML 基准测试结果¶
OpenML 于 2023 年 11 月 16 日发布了官方 2023 年 AutoML 基准测试结果。他们的结果显示,AutoGluon 0.8 在各种任务中是 AutoML 系统领域的最新技术:“总体而言,在模型性能方面,AutoGluon 在我们的基准测试中始终具有最高的平均排名。”现在我们展示 AutoGluon 1.0 甚至比 AutoGluon 0.8 取得了更优异的结果!
下面是针对 OpenML AutoML 基准测试的 1040 个任务进行的比较。LightGBM、XGBoost 和 CatBoost 的结果是通过 AutoGluon 获得的,其他方法来自官方 2023 年 AutoML 基准测试结果。AutoGluon 1.0 相对于传统表格模型具有 95% 以上的胜率,其中对 LightGBM 的胜率为 99%,对 XGBoost 的胜率为 100%。AutoGluon 1.0 对其他 AutoML 系统的胜率在 82% 到 94% 之间。对于所有方法,AutoGluon 都能实现 >10% 的平均损失改进(例如:从 90% 的准确率提高到 91% 的准确率就是 10% 的损失改进)。AutoGluon 1.0 在 63% 的任务中排名第一,而 lightautoml 排名第二,占 12%(AutoGluon 0.8 此前排名第一的比例为 48%)。AutoGluon 1.0 甚至比 AutoGluon 0.8 平均损失改进了 7.4%!
方法 |
AG 胜率 |
AG 损失改进 |
缩放损失 |
排名 |
最佳 |
|---|---|---|---|---|---|
AutoGluon 1.0 (最佳, 4h8c) |
- |
- |
0.04 |
1.95 |
63% |
lightautoml (2023, 4h8c) |
84% |
12.0% |
0.2 |
4.78 |
12% |
H2OAutoML (2023, 4h8c) |
94% |
10.8% |
0.17 |
4.98 |
1% |
FLAML (2023, 4h8c) |
86% |
16.7% |
0.23 |
5.29 |
5% |
MLJAR (2023, 4h8c) |
82% |
23.0% |
0.33 |
5.53 |
6% |
autosklearn (2023, 4h8c) |
91% |
12.5% |
0.22 |
6.07 |
4% |
GAMA (2023, 4h8c) |
86% |
15.4% |
0.28 |
6.13 |
5% |
CatBoost (2023, 4h8c) |
95% |
18.2% |
0.28 |
6.89 |
3% |
TPOT (2023, 4h8c) |
91% |
23.1% |
0.4 |
8.15 |
1% |
LightGBM (2023, 4h8c) |
99% |
23.6% |
0.4 |
8.95 |
0% |
XGBoost (2023, 4h8c) |
100% |
24.1% |
0.43 |
9.5 |
0% |
RandomForest (2023, 4h8c) |
97% |
25.1% |
0.53 |
9.78 |
1% |
AutoGluon 1.0 不仅更准确,而且由于我们在低内存训练期间使用了新的 Ray 子进程,稳定性也更高,在 AutoML 基准测试中实现了 0 次任务失败。
AutoGluon 1.0 能够实现任何 AutoML 系统中最快的推理吞吐量,同时仍能获得最先进的结果。通过指定 infer_limit fit 参数,用户可以在准确性和推理速度之间进行权衡,以满足他们的需求。
如下图所示,AutoGluon 1.0 在质量和推理吞吐量方面设定了帕累托前沿,相对于所有其他 AutoML 系统实现了帕累托支配。AutoGluon 1.0 High 以 8 倍的推理速度和 8 倍低的磁盘使用量实现了优于 AutoGluon 0.8 Best 的性能!
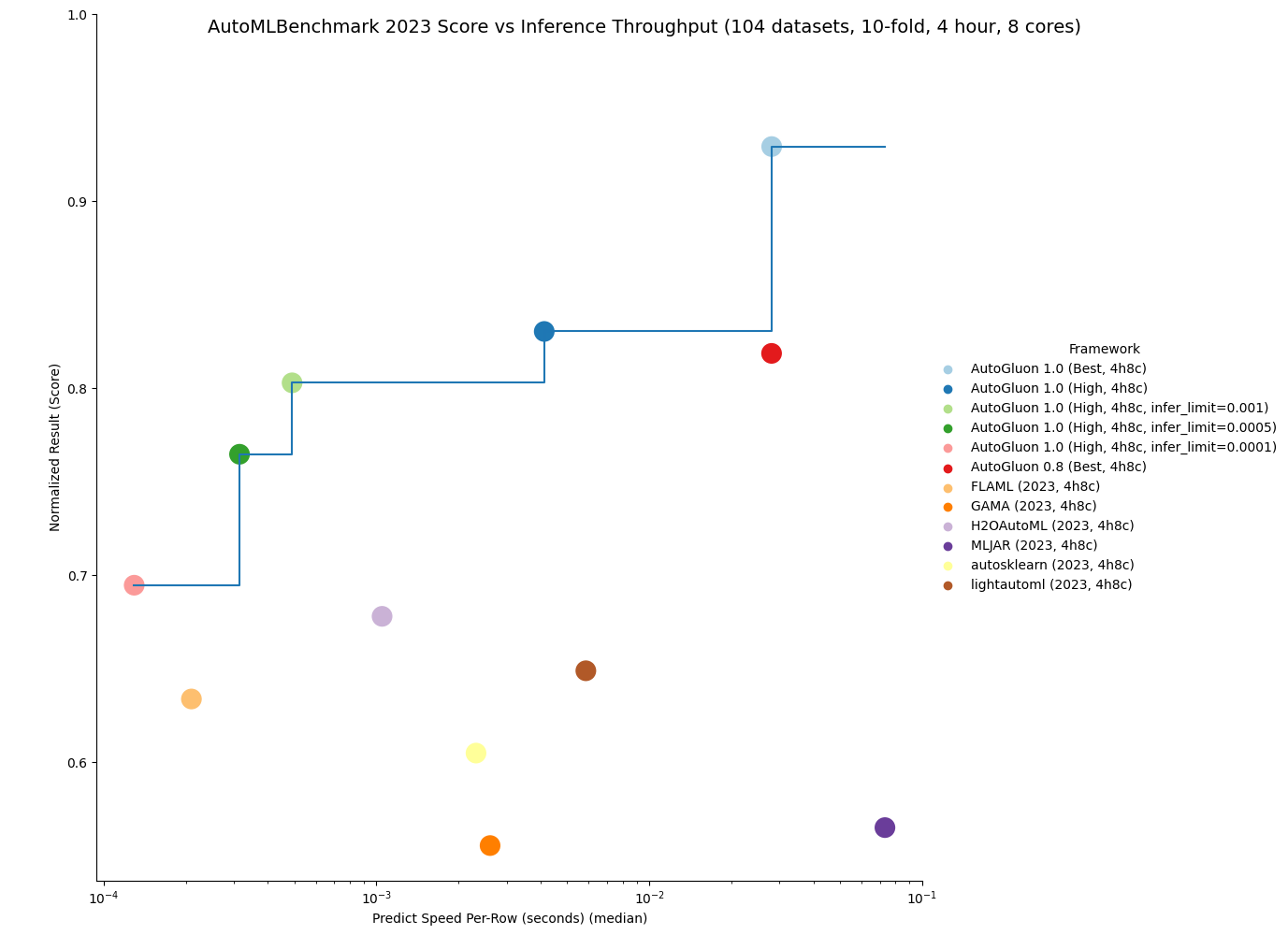
您可以在这里获取结果的更多详细信息。
我们很高兴看到我们的用户可以利用 AutoGluon 1.0 的增强性能取得哪些成就。一如既往,我们将在未来的版本中继续改进 AutoGluon,为所有人推动 AutoML 的界限。
AutoGluon 多模态 (AutoMM) 亮点一览¶

AutoMM 的独特性¶
AutoGluon 多模态 (AutoMM) 与其他主要关注表格数据分类或回归的开源 AutoML 工具箱(如 AutosSklearn、LightAutoML、H2OAutoML、FLAML、MLJAR、TPOT 和 GAMA)不同。AutoMM 旨在对图像、文本、表格和文档等多种模态的基础模型进行微调,无论是单独使用还是组合使用。它为分类、回归、目标检测、命名实体识别、语义匹配和图像分割等任务提供了广泛的功能。相比之下,其他 AutoML 系统对图像或文本的支持通常有限,通常使用少数预训练模型(如 EfficientNet)或手工规则(如 词袋模型)作为特征提取器。它们通常依赖于传统模型或简单的神经网络。AutoMM 提供了一种独特的全面且通用的 AutoML 方法,是唯一支持灵活多模态和广泛任务的 AutoML 系统。下面提供了详细说明对各种数据模态、任务和模型类型支持的比较表。
数据 |
任务 |
模型 |
||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
图像 |
文本 |
表格数据 |
文档 |
任意组合 |
分类 |
回归 |
目标检测 |
语义匹配 |
命名实体识别 |
图像分割 |
传统模型 |
深度学习模型 |
基础模型 |
|
LightAutoML |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
|||||||
H2OAutoML |
✓ |
✓ |
✓ |
✓ |
||||||||||
FLAML |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
|||||||
MLJAR |
✓ |
✓ |
✓ |
✓ |
||||||||||
AutoSklearn |
✓ |
✓ |
✓ |
✓ |
✓ |
|||||||||
GAMA |
✓ |
✓ |
✓ |
✓ |
||||||||||
TPOT |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
||||||||
AutoMM |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
特别感谢¶
在本亮点部分结束之际,我们要感谢 Pieter Gijsbers、Sébastien Poirier、Erin LeDell、Joaquin Vanschoren 以及其他 AutoML Benchmark 作者,他们为提供一个共享且广泛的基准测试平台,以监测 AutoML 领域的进展发挥了关键作用。他们的支持对 AutoGluon 项目的持续发展至关重要。
我们还要感谢 Frank Hutter,他仍然是 AutoML 领域的领导者,感谢他在 2022 年和 2023 年组织了 AutoML 会议,将社区聚集在一起分享想法并就共同的愿景达成一致。
最后,我们要感谢 Alex Smola 和 Mu Li 在亚马逊倡导开源软件,使这个项目成为可能。
额外特别感谢¶
特别感谢 @LennartPurucker 领导动态堆叠 (dynamic stacking) 的开发
特别感谢 @ddelange 帮助添加 Python 3.11 支持
特别感谢 @mglowacki100 提供了大量反馈和建议
特别感谢 @Harry-zzh 贡献了新的语义分割问题类型
通用¶
亮点¶
其他增强¶
依赖更新¶
将 torch 升级到
>=2.0,<2.2@zhiqiangdon @yinweisu @shchur (#3404, #3587, #3588)将 numpy 升级到
>=1.21,<1.29@prateekdesai04 (#3709)将 scikit-learn 升级到
>=1.3,<1.5@yinweisu @tonyhoo @shchur (#3498)将 scipy 升级到
>=1.5.4,<1.13@prateekdesai04 (#3709)将 LightGBM 升级到
>=3.3,<4.2@mglowacki100 @prateekdesai04 @Innixma (#3427, #3709, #3733)
表格数据¶
亮点¶
AutoGluon 1.0 提供了预测质量的重大增强,在表格数据建模领域树立了新的标杆。详情请参阅上方的亮点部分!
新功能¶
添加了
dynamic_stacking预测器拟合参数以缓解堆叠过拟合 @LennartPurucker @Innixma (#3616)将零样本 HPO 学习到的组合 (zeroshot-HPO learned portfolio) 添加为
best_quality和high_quality预设的新超参数。 @Innixma @geoalgo (#3750)为 TabularPredictor 添加了实验性 scikit-learn API 兼容包装器。您可以通过
from autogluon.tabular.experimental import TabularClassifier, TabularRegressor访问它们。 @Innixma (#3769)添加了增强的 FT-Transformer @taoyang1122 @Innixma (#3621, #3644, #3692)
增加了
predictor.simulation_artifact(),以支持与 TabRepo 集成 @Innixma (#3555)
性能提升¶
通过输出裁剪增强了 FastAI 模型在回归任务上的质量 @LennartPurucker @Innixma (#3597)
增加了跳跃连接加权集成 (Skip-connection Weighted Ensemble) @LennartPurucker (#3598)
通过使用 Ray 进程进行顺序拟合修复了内存泄漏问题 @LennartPurucker (#3614)
其他增强功能¶
多层堆叠现在产生确定性结果 @LennartPurucker (#3573)
各种模型依赖更新 @mglowacki100 (#3373)
错误修复/代码和文档改进¶
AutoMM¶
AutoGluon 多模态 (AutoMM) 旨在通过仅三行代码即可简化基础模型用于下游应用的微调过程。它与流行的模型动物园无缝集成,例如 HuggingFace Transformers、TIMM 和 MMDetection,支持多种数据模态,包括图像、文本、表格和文档数据,无论是单独使用还是组合使用。
新特性¶
语义分割
引入新的问题类型
semantic_segmentation,支持用三行代码微调 Segment Anything Model (SAM)。 @Harry-zzh @zhiqiangdon (#3645, #3677, #3697, #3711, #3722, #3728)增加了来自不同领域(包括自然图像、农业、遥感和医疗保健)的全面基准测试。
利用参数高效微调 (PEFT) LoRA,在广泛的基准测试中展示了始终优于其他替代方法(VPT、adaptor、BitFit、SAM-adaptor 和 LST)的性能。
添加了一个语义分割教程 @zhiqiangdon (#3716)。
默认使用 SAM-ViT Huge(需要大于 25GB 的 GPU 内存)。
少样本分类
新增了
few_shot_classification问题类型,用于在图像或文本上训练少样本分类器。 @zhiqiangdon (#3662, #3681, #3695)利用图像/文本基础模型提取特征并训练 SVM 分类器。
新增了一个少样本分类教程。 @zhiqiangdon (#3662)
支持 torch.compile 以加速训练(实验性,需要 torch >=2.2) @zhiqiangdon (#3520)。
性能提升¶
改进了默认图像骨干网络,在图像基准测试中取得了 100% 的胜率。 @taoyang1122 (#3738)
将 MLP 替换为 FT-Transformer 作为默认表格骨干网络,在文本+表格基准测试中取得了 67% 的胜率。 @taoyang1122 (#3732)
同时使用改进的默认图像骨干网络和 FT-Transformer,在文本+表格+图像基准测试中取得了 62% 的胜率。 @taoyang1122 (#3732, #3738)
稳定性增强¶
启用了严格的多 GPU CI 测试。 @prateekdesai04 (#3566)
修复了多 GPU 问题。 @FANGAreNotGnu (#3617 #3665 #3684 #3691, #3639, #3618)
可用性增强¶
支持自定义评估指标,允许定义自定义指标对象并将其传递给
eval_metric参数。 @taoyang1122 (#3548)支持在笔记本中进行多 GPU 训练(实验性)。 @zhiqiangdon (#3484)
改进了包含系统信息的日志记录。 @zhiqiangdon (#3735)
可伸缩性改进¶
新的 Learner 类设计的引入,使得 AutoMM 更容易支持新的任务和数据模态,增强了整体可伸缩性。 @zhiqiangdon (#3650, #3685, #3735)
其他增强功能¶
新增了
hf_text.use_fast选项,用于在hf_text模型中自定义快速分词器的使用。 @zhiqiangdon (#3379)新增了备用评估/验证指标,支持
f1_macro、f1_micro和f1_weighted。 @FANGAreNotGnu (#3696)支持使用 DDP 策略进行多 GPU 推理。 @zhiqiangdon (#3445, #3451)
Torch 升级到 2.0。 @zhiqiangdon (#3404)
Lightning 升级到 2.0 @zhiqiangdon (#3419)
Torchmetrics 升级到 1.0 @zhiqiangdon (#3422)
代码改进¶
通过 Learner 类对 AutoMM 进行了重构,改进了设计。 @zhiqiangdon (#3650, #3685, #3735)
FT-Transformer 重构。 @taoyang1122 (#3621, #3700)
重构了目标检测、语义分割和 NER 的可视化器。 @zhiqiangdon (#3716)
其他代码重构/清理: @zhiqiangdon @FANGAreNotGnu (#3383 #3399 #3434 #3667 #3684 #3695)
错误修复/文档改进¶
修复了一个 ONNX 导出问题。 @AnirudhDagar (#3725)
改进了 AutoMM 介绍以提高清晰度。 @zhiqiangdon (#3388 #3726)
改进了 AutoMM API 文档。 @zhiqiangdon @AnirudhDagar (#3772 #3777)
其他错误修复 @zhiqiangdon @FANGAreNotGnu @taoyang1122 @tonyhoo @rsj123 @AnirudhDagar (#3384, #3424, #3526, #3593, #3615, #3638, #3674, #3693, #3702, #3690, #3729, #3736, #3474, #3456, #3590, #3660)
其他文档改进 @zhiqiangdon @FANGAreNotGnu @taoyang1122 (#3397, #3461, #3579, #3670, #3699, #3710, #3716, #3737, #3744, #3745, #3680)
时间序列 (TimeSeries)¶
亮点¶
AutoGluon 1.0 为 TimeSeries 模块带来了众多可用性和性能改进。其中包括对缺失数据和不规则时间序列的自动处理、新的预测指标(包括自定义指标支持)、高级时间序列交叉验证选项以及新的预测模型。AutoGluon 在预测准确性方面取得了最先进的结果,与其他流行的预测框架相比,胜率超过 70%。
新特性¶
新的预测指标
WAPE、RMSSE、SQL+ 改进的指标文档 @melopeo @shchur (#3747, #3632, #3510, #3490)提高了鲁棒性:
TimeSeriesPredictor现在可以处理包含所有 pandas 频率、不规则时间戳或由NaN表示的缺失值的数据 @shchur (#3563, #3454)新模型:基于共形预测 (conformal prediction) 的间歇需求预测模型(
ADIDA,CrostonClassic,CrostonOptimized,CrostonSBA,IMAPA);来自 GluonTS 的WaveNet和NPTS;新的基线模型(Average,SeasonalAverage,Zero) @canerturkmen @shchur (#3706, #3742, #3606, #3459)高级交叉验证选项:通过
refit_every_n_windows参数避免为每个验证窗口重新训练模型,或者通过TimeSeriesPredictor.fit的val_step_size参数调整验证窗口之间的步长 @shchur (#3704, #3537)
增强功能¶
性能改进¶
错误修复/代码和文档改进¶
探索性数据分析 (EDA)¶
EDA 模块将在稍后发布,因为它需要额外的开发工作才能为 1.0 做好准备。当 EDA 准备好发布时,我们将发布公告。目前,请继续使用 "autogluon.eda==0.8.2"。
弃用¶
通用¶
表格 (Tabular)¶
如果使用已弃用的方法,Tabular 将记录警告。计划在 AutoGluon 1.2 中移除已弃用的方法 @Innixma (#3701)
autogluon.tabular.TabularPredictorpredictor.get_model_names()->predictor.model_names()predictor.get_model_names_persisted()->predictor.model_names(persisted=True)predictor.compile_models()->predictor.compile()predictor.persist_models()->predictor.persist()predictor.unpersist_models()->predictor.unpersist()predictor.get_model_best()->predictor.model_bestpredictor.get_pred_from_proba()->predictor.predict_from_proba()predictor.get_oof_pred_proba()->predictor.predict_proba_oof()predictor.get_oof_pred()->predictor.predict_oof()predictor.get_model_full_dict()->predictor.model_refit_map()predictor.get_size_disk()->predictor.disk_usage()predictor.get_size_disk_per_file()->predictor.disk_usage_per_file()predictor.leaderboard()的silent参数已弃用,替换为display,默认为 Falsepredictor.evaluate()和predictor.evaluate_predictions()也一样
AutoMM¶
弃用了
FewShotSVMPredictor,推荐使用新的few_shot_classification问题类型 @zhiqiangdon (#3699)弃用了
AutoMMPredictor,推荐使用MultiModalPredictor@zhiqiangdon (#3650)autogluon.multimodal.MultiModalPredictor弃用了 fit API 中的
config参数。 @zhiqiangdon (#3679)弃用了 init API 中的
init_scratch和pipeline参数 @zhiqiangdon (#3668)
时间序列 (TimeSeries)¶
autogluon.timeseries.TimeSeriesPredictor弃用参数
TimeSeriesPredictor(ignore_time_index: bool)。现在,如果数据包含不规则时间戳,可以通过data = data.convert_frequency(freq)将其转换为规则频率,或者在创建预测器时提供频率,例如TimeSeriesPredictor(freq=freq)。predictor.evaluate()现在返回一个字典(之前返回一个浮点数)predictor.score()->predictor.evaluate()predictor.get_model_names()->predictor.model_names()predictor.get_model_best()->predictor.model_best指标
"mean_wQuantileLoss"已重命名为"WQL"predictor.leaderboard()的silent参数已弃用,替换为display,默认为 False在
predictor.fit()中将hyperparameters设置为字符串时,现在支持的值为"default"、"light"和"very_light"
autogluon.timeseries.TimeSeriesDataFramedf.to_regular_index()->df.convert_frequency()弃用方法
df.get_reindexed_view()。请参阅上面TimeSeriesPredictor下关于ignore_time_index的弃用说明,了解如何处理不规则时间戳。
模型
所有基于 MXNet 的模型(
DeepARMXNet、MQCNNMXNet、MQRNNMXNet、SimpleFeedForwardMXNet、TemporalFusionTransformerMXNet、TransformerMXNet)已被移除。来自 Statmodels 的统计模型(
ARIMA、Theta、ETS)已被来自 StatsForecast 的对应模型取代 (#3513)。请注意,这些模型的超参数名称现在不同。DirectTabular现在使用mlforecast后端实现(与RecursiveTabular相同),模型的大多数超参数名称已更改。
已弃用
autogluon.timeseries.TimeSeriesEvaluator。请改用autogluon.timeseries.metrics中提供的指标。已弃用
autogluon.timeseries.splitter.MultiWindowSplitter和autogluon.timeseries.splitter.LastWindowSplitter。请改用TimeSeriesPredictor.fit的num_val_windows和val_step_size参数(或者使用autogluon.timeseries.splitter.ExpandingWindowSplitter)。
论文¶
AutoGluon-TimeSeries:面向概率时间序列预测的 AutoML¶
我们在 AutoML Conference 2023 上发表了一篇关于 AutoGluon-TimeSeries 的论文(论文链接,YouTube 视频)。在论文中,我们对 AutoGluon 和流行的开源预测框架(包括 DeepAR、TFT、AutoARIMA、AutoETS、AutoPyTorch)进行了基准测试。AutoGluon 在点预测和概率预测方面都取得了 SOTA 结果,甚至相对于最优模型组合(事后来看)取得了 65% 的胜率。
TabRepo:大规模表格模型评估库及其 AutoML 应用¶
我们在 arXiv 上发表了一篇关于表格零样本 HPO 集成仿真的论文(论文链接,GitHub)。这篇论文是实现 AutoGluon 1.0 中性能改进的关键,我们计划继续开发代码库以支持未来的增强功能。
XTab:表格 Transformer 的跨表预训练¶
我们在 ICML 2023 上发表了一篇关于表格 Transformer 预训练的论文(论文链接,GitHub)。在论文中,我们展示了表格深度学习模型的最先进性能,包括能够匹敌 XGBoost 和 LightGBM 模型的性能。虽然预训练的 Transformer 尚未集成到 AutoGluon 中,但我们计划在未来的版本中集成。
在特征空间中学习多模态数据增强¶
我们关于学习多模态数据增强的论文已被 ICLR 2023 接受(论文链接,GitHub)。这篇论文引入了一个即插即用模块,用于在特征空间中学习多模态数据增强,对模态的身份或模态之间的关系没有约束。我们展示了它可以 (1) 提高多模态深度学习架构的性能,(2) 应用于以前未曾考虑过的模态组合,以及 (3) 在包含图像、文本和表格数据的广泛应用中实现最先进的结果。这项工作尚未集成到 AutoGluon 中,但我们计划在未来的版本中集成。
基于可控扩散模型的目标检测数据增强¶
我们关于生成式目标检测数据增强的论文已被 WACV 2024 接受(论文和 GitHub 链接即将发布)。这篇论文提出了一种基于可控扩散模型和 CLIP 的数据增强流程,通过视觉先验生成来指导生成,并通过类别校准的 CLIP 分数进行后过滤以控制其质量。我们证明了在使用我们的增强流程和不同的检测器时,性能在各种任务和设置中得到提升。虽然扩散模型目前尚未集成到 AutoGluon 中,但我们计划在未来的版本中集成这些数据增强技术。
将图像基础模型应用于视频理解¶
我们在 ICLR 2023 上发表了一篇关于如何有效地将图像基础模型应用于视频理解的论文(论文链接,GitHub)。这篇论文引入了空间适应、时间适应和联合适应,逐步赋予冻结的图像模型时空推理能力。所提出的方法实现了与传统完全微调相当甚至更好的性能,同时大大节省了大型基础模型的训练成本。