AutoMM for Text - 快速入门¶
![]()

MultiModalPredictor 可以解决数据包含图像、文本、数值或类别特征的问题。为了快速入门,我们首先演示如何使用它来解决仅包含文本的问题。出于演示目的,我们选择两个经典的自然语言处理(NLP)问题:
在此,我们将 NLP 数据集格式化为数据表,其中特征列包含文本字段,标签列包含数值(回归)/类别(分类)值。表中的每一行对应一个训练样本。
%matplotlib inline
import numpy as np
import warnings
import matplotlib.pyplot as plt
warnings.filterwarnings('ignore')
np.random.seed(123)
情感分析任务¶
首先,我们考虑 Stanford Sentiment Treebank (SST) 数据集,该数据集包含电影评论及其相关情感。给定一条新的电影评论,目标是预测文本中反映的情感(在这种情况下是二分类,如果评论传达正面观点则标记为 1,否则标记为 0)。让我们首先加载并查看数据,注意标签存储在名为 label 的列中。
from autogluon.core.utils.loaders import load_pd
train_data = load_pd.load('https://autogluon-text.s3-accelerate.amazonaws.com/glue/sst/train.parquet')
test_data = load_pd.load('https://autogluon-text.s3-accelerate.amazonaws.com/glue/sst/dev.parquet')
subsample_size = 1000 # subsample data for faster demo, try setting this to larger values
train_data = train_data.sample(n=subsample_size, random_state=0)
train_data.head(10)
| 句子 | 标签 | |
|---|---|---|
| 43787 | 在最精彩的部分令人非常愉快 | 1 |
| 16159 | ,美国奶茶足以让你收起... | 0 |
| 59015 | 太像 Ram Dass 的广告了... | 0 |
| 5108 | 一个激动人心的视觉片段 | 1 |
| 67052 | 酷炫的视觉倒放 | 1 |
| 35938 | 硬地 | 0 |
| 49879 | 那个引人注目、悄悄脆弱的个性... | 1 |
| 51591 | Pan Nalin 的阐述美丽而神秘... | 1 |
| 56780 | 精彩绝伦的怪诞 | 1 |
| 28518 | 最美丽,最令人回味 | 1 |
上面显示的数据碰巧存储为 Parquet 格式,但您也可以直接从 CSV 文件或其他等效格式 load() 数据。虽然这里我们从 AWS S3 云存储加载文件,但这些文件也可以是您机器上的本地文件。加载后,train_data 只是一个 Pandas DataFrame,其中每一行代表一个不同的训练示例。
训练¶
为了确保本教程快速运行,我们仅使用 1000 个训练示例的子集调用 fit(),并将运行时长限制在大约 1 分钟。为了在您的应用中获得合理的性能,建议设置更长的 time_limit(例如 1 小时),或者完全不指定 time_limit(即 time_limit=None)。
from autogluon.multimodal import MultiModalPredictor
import uuid
model_path = f"./tmp/{uuid.uuid4().hex}-automm_sst"
predictor = MultiModalPredictor(label='label', eval_metric='acc', path=model_path)
predictor.fit(train_data, time_limit=180)
=================== System Info ===================
AutoGluon Version: 1.3.1b20250508
Python Version: 3.11.9
Operating System: Linux
Platform Machine: x86_64
Platform Version: #1 SMP Wed Mar 12 14:53:59 UTC 2025
CPU Count: 8
Pytorch Version: 2.6.0+cu124
CUDA Version: 12.4
Memory Avail: 28.36 GB / 30.95 GB (91.6%)
Disk Space Avail: 185.24 GB / 255.99 GB (72.4%)
===================================================
AutoGluon infers your prediction problem is: 'binary' (because only two unique label-values observed).
2 unique label values: [np.int64(1), np.int64(0)]
If 'binary' is not the correct problem_type, please manually specify the problem_type parameter during Predictor init (You may specify problem_type as one of: ['binary', 'multiclass', 'regression', 'quantile'])
AutoMM starts to create your model. ✨✨✨
To track the learning progress, you can open a terminal and launch Tensorboard:
```shell
# Assume you have installed tensorboard
tensorboard --logdir /home/ci/autogluon/docs/tutorials/multimodal/text_prediction/tmp/fbf6a45517624d23a619faf83d33e4c1-automm_sst
```
Seed set to 0
GPU Count: 1
GPU Count to be Used: 1
Using 16bit Automatic Mixed Precision (AMP)
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
HPU available: False, using: 0 HPUs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params | Mode
---------------------------------------------------------------------------
0 | model | HFAutoModelForTextPrediction | 108 M | train
1 | validation_metric | MulticlassAccuracy | 0 | train
2 | loss_func | CrossEntropyLoss | 0 | train
---------------------------------------------------------------------------
108 M Trainable params
0 Non-trainable params
108 M Total params
435.573 Total estimated model params size (MB)
229 Modules in train mode
0 Modules in eval mode
Epoch 0, global step 3: 'val_accuracy' reached 0.55500 (best 0.55500), saving model to '/home/ci/autogluon/docs/tutorials/multimodal/text_prediction/tmp/fbf6a45517624d23a619faf83d33e4c1-automm_sst/epoch=0-step=3.ckpt' as top 3
Epoch 0, global step 7: 'val_accuracy' reached 0.59500 (best 0.59500), saving model to '/home/ci/autogluon/docs/tutorials/multimodal/text_prediction/tmp/fbf6a45517624d23a619faf83d33e4c1-automm_sst/epoch=0-step=7.ckpt' as top 3
Epoch 1, global step 10: 'val_accuracy' reached 0.63000 (best 0.63000), saving model to '/home/ci/autogluon/docs/tutorials/multimodal/text_prediction/tmp/fbf6a45517624d23a619faf83d33e4c1-automm_sst/epoch=1-step=10.ckpt' as top 3
Epoch 1, global step 14: 'val_accuracy' reached 0.72000 (best 0.72000), saving model to '/home/ci/autogluon/docs/tutorials/multimodal/text_prediction/tmp/fbf6a45517624d23a619faf83d33e4c1-automm_sst/epoch=1-step=14.ckpt' as top 3
Epoch 2, global step 17: 'val_accuracy' reached 0.86500 (best 0.86500), saving model to '/home/ci/autogluon/docs/tutorials/multimodal/text_prediction/tmp/fbf6a45517624d23a619faf83d33e4c1-automm_sst/epoch=2-step=17.ckpt' as top 3
Epoch 2, global step 21: 'val_accuracy' reached 0.80500 (best 0.86500), saving model to '/home/ci/autogluon/docs/tutorials/multimodal/text_prediction/tmp/fbf6a45517624d23a619faf83d33e4c1-automm_sst/epoch=2-step=21.ckpt' as top 3
Epoch 3, global step 24: 'val_accuracy' reached 0.88500 (best 0.88500), saving model to '/home/ci/autogluon/docs/tutorials/multimodal/text_prediction/tmp/fbf6a45517624d23a619faf83d33e4c1-automm_sst/epoch=3-step=24.ckpt' as top 3
Epoch 3, global step 28: 'val_accuracy' reached 0.88000 (best 0.88500), saving model to '/home/ci/autogluon/docs/tutorials/multimodal/text_prediction/tmp/fbf6a45517624d23a619faf83d33e4c1-automm_sst/epoch=3-step=28.ckpt' as top 3
Epoch 4, global step 31: 'val_accuracy' was not in top 3
Epoch 4, global step 35: 'val_accuracy' reached 0.90500 (best 0.90500), saving model to '/home/ci/autogluon/docs/tutorials/multimodal/text_prediction/tmp/fbf6a45517624d23a619faf83d33e4c1-automm_sst/epoch=4-step=35.ckpt' as top 3
Epoch 5, global step 38: 'val_accuracy' was not in top 3
Epoch 5, global step 42: 'val_accuracy' reached 0.90500 (best 0.90500), saving model to '/home/ci/autogluon/docs/tutorials/multimodal/text_prediction/tmp/fbf6a45517624d23a619faf83d33e4c1-automm_sst/epoch=5-step=42.ckpt' as top 3
Epoch 6, global step 45: 'val_accuracy' reached 0.91500 (best 0.91500), saving model to '/home/ci/autogluon/docs/tutorials/multimodal/text_prediction/tmp/fbf6a45517624d23a619faf83d33e4c1-automm_sst/epoch=6-step=45.ckpt' as top 3
Epoch 6, global step 49: 'val_accuracy' was not in top 3
Epoch 7, global step 52: 'val_accuracy' reached 0.92000 (best 0.92000), saving model to '/home/ci/autogluon/docs/tutorials/multimodal/text_prediction/tmp/fbf6a45517624d23a619faf83d33e4c1-automm_sst/epoch=7-step=52.ckpt' as top 3
Epoch 7, global step 56: 'val_accuracy' reached 0.91000 (best 0.92000), saving model to '/home/ci/autogluon/docs/tutorials/multimodal/text_prediction/tmp/fbf6a45517624d23a619faf83d33e4c1-automm_sst/epoch=7-step=56.ckpt' as top 3
Epoch 8, global step 59: 'val_accuracy' was not in top 3
Epoch 8, global step 63: 'val_accuracy' was not in top 3
Time limit reached. Elapsed time is 0:03:03. Signaling Trainer to stop.
Start to fuse 3 checkpoints via the greedy soup algorithm.
Using default `ModelCheckpoint`. Consider installing `litmodels` package to enable `LitModelCheckpoint` for automatic upload to the Lightning model registry.
Using default `ModelCheckpoint`. Consider installing `litmodels` package to enable `LitModelCheckpoint` for automatic upload to the Lightning model registry.
Using default `ModelCheckpoint`. Consider installing `litmodels` package to enable `LitModelCheckpoint` for automatic upload to the Lightning model registry.
AutoMM has created your model. 🎉🎉🎉
To load the model, use the code below:
```python
from autogluon.multimodal import MultiModalPredictor
predictor = MultiModalPredictor.load("/home/ci/autogluon/docs/tutorials/multimodal/text_prediction/tmp/fbf6a45517624d23a619faf83d33e4c1-automm_sst")
```
If you are not satisfied with the model, try to increase the training time,
adjust the hyperparameters (https://autogluon.cn/stable/tutorials/multimodal/advanced_topics/customization.html),
or post issues on GitHub (https://github.com/autogluon/autogluon/issues).
<autogluon.multimodal.predictor.MultiModalPredictor at 0x7f43b1f8ea10>
上面我们指定:名为 label 的列包含要预测的标签值,AutoGluon 应该优化预测以达到准确率评估指标,训练好的模型应该保存在 automm_sst 文件夹中,并且训练应该运行大约 60 秒。
评估¶
训练后,我们可以轻松地在格式与训练数据相似的单独测试数据上评估预测器的性能。
test_score = predictor.evaluate(test_data)
print(test_score)
{'accuracy': 0.9036697247706422}
Using default `ModelCheckpoint`. Consider installing `litmodels` package to enable `LitModelCheckpoint` for automatic upload to the Lightning model registry.
默认情况下,evaluate() 将报告先前指定的评估指标,在本例中为 accuracy。您还可以在调用 evaluate 时指定其他评估指标,例如 F1 分数。
test_score = predictor.evaluate(test_data, metrics=['acc', 'f1'])
print(test_score)
{'acc': 0.9036697247706422, 'f1': 0.9068736141906873}
Using default `ModelCheckpoint`. Consider installing `litmodels` package to enable `LitModelCheckpoint` for automatic upload to the Lightning model registry.
预测¶
您可以通过调用 predictor.predict() 轻松获取这些模型的预测结果。
sentence1 = "it's a charming and often affecting journey."
sentence2 = "It's slow, very, very, very slow."
predictions = predictor.predict({'sentence': [sentence1, sentence2]})
print('"Sentence":', sentence1, '"Predicted Sentiment":', predictions[0])
print('"Sentence":', sentence2, '"Predicted Sentiment":', predictions[1])
"Sentence": it's a charming and often affecting journey. "Predicted Sentiment": 1
"Sentence": It's slow, very, very, very slow. "Predicted Sentiment": 0
Using default `ModelCheckpoint`. Consider installing `litmodels` package to enable `LitModelCheckpoint` for automatic upload to the Lightning model registry.
对于分类任务,您可以请求预测的类别概率,而不是预测的类别。
probs = predictor.predict_proba({'sentence': [sentence1, sentence2]})
print('"Sentence":', sentence1, '"Predicted Class-Probabilities":', probs[0])
print('"Sentence":', sentence2, '"Predicted Class-Probabilities":', probs[1])
"Sentence": it's a charming and often affecting journey. "Predicted Class-Probabilities": [1.3711806e-04 9.9986291e-01]
"Sentence": It's slow, very, very, very slow. "Predicted Class-Probabilities": [0.9974837 0.00251636]
Using default `ModelCheckpoint`. Consider installing `litmodels` package to enable `LitModelCheckpoint` for automatic upload to the Lightning model registry.
我们可以同样轻松地对整个数据集生成预测。
test_predictions = predictor.predict(test_data)
test_predictions.head()
Using default `ModelCheckpoint`. Consider installing `litmodels` package to enable `LitModelCheckpoint` for automatic upload to the Lightning model registry.
0 1
1 0
2 1
3 1
4 0
Name: label, dtype: int64
保存与加载¶
训练好的预测器在 fit() 结束时会自动保存,您可以轻松地重新加载它。
警告
MultiModalPredictor.load() 隐式使用了 pickle 模块,已知该模块不安全。可以构造恶意的 pickle 数据,并在反序列化(unpickling)期间执行任意代码。切勿加载可能来自不受信任源或可能已被篡改的数据。仅加载您信任的数据。
loaded_predictor = MultiModalPredictor.load(model_path)
loaded_predictor.predict_proba({'sentence': [sentence1, sentence2]})
Load pretrained checkpoint: /home/ci/autogluon/docs/tutorials/multimodal/text_prediction/tmp/fbf6a45517624d23a619faf83d33e4c1-automm_sst/model.ckpt
Using default `ModelCheckpoint`. Consider installing `litmodels` package to enable `LitModelCheckpoint` for automatic upload to the Lightning model registry.
array([[1.3765464e-04, 9.9986231e-01],
[9.9748850e-01, 2.5114634e-03]], dtype=float32)
您也可以通过调用 .save() 将预测器保存到任意位置。
new_model_path = f"./tmp/{uuid.uuid4().hex}-automm_sst"
loaded_predictor.save(new_model_path)
loaded_predictor2 = MultiModalPredictor.load(new_model_path)
loaded_predictor2.predict_proba({'sentence': [sentence1, sentence2]})
Load pretrained checkpoint: /home/ci/autogluon/docs/tutorials/multimodal/text_prediction/tmp/c44bb497a5ee4831924c6d3326d02d37-automm_sst/model.ckpt
Using default `ModelCheckpoint`. Consider installing `litmodels` package to enable `LitModelCheckpoint` for automatic upload to the Lightning model registry.
array([[1.3765464e-04, 9.9986231e-01],
[9.9748850e-01, 2.5114634e-03]], dtype=float32)
提取嵌入¶
您还可以使用训练好的预测器来提取嵌入,将数据表的每一行映射到从该行中间神经网络表示中提取的嵌入向量。
embeddings = predictor.extract_embedding(test_data)
print(embeddings.shape)
(872, 768)
Using default `ModelCheckpoint`. Consider installing `litmodels` package to enable `LitModelCheckpoint` for automatic upload to the Lightning model registry.
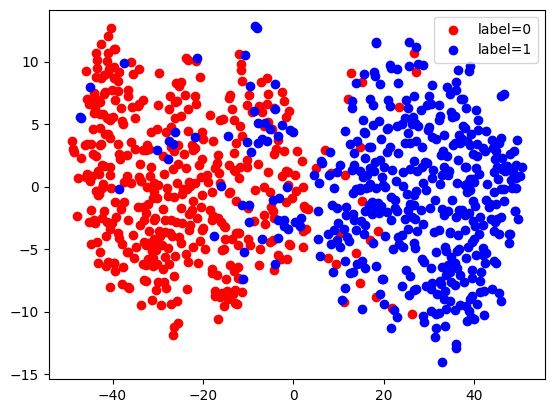
这里,我们使用 TSNE 对这些提取的嵌入进行可视化。我们可以看到存在与我们的两个标签对应的两个聚类,因为该网络已经过训练,可以区分这些标签。
from sklearn.manifold import TSNE
X_embedded = TSNE(n_components=2, random_state=123).fit_transform(embeddings)
for val, color in [(0, 'red'), (1, 'blue')]:
idx = (test_data['label'].to_numpy() == val).nonzero()
plt.scatter(X_embedded[idx, 0], X_embedded[idx, 1], c=color, label=f'label={val}')
plt.legend(loc='best')
<matplotlib.legend.Legend at 0x7f439c3a0d10>
句子相似度任务¶
接下来,让我们使用 MultiModalPredictor 训练一个模型,用于评估两个句子的语义相似度。我们使用 Semantic Textual Similarity Benchmark 数据集进行说明。
sts_train_data = load_pd.load('https://autogluon-text.s3-accelerate.amazonaws.com/glue/sts/train.parquet')[['sentence1', 'sentence2', 'score']]
sts_test_data = load_pd.load('https://autogluon-text.s3-accelerate.amazonaws.com/glue/sts/dev.parquet')[['sentence1', 'sentence2', 'score']]
sts_train_data.head(10)
Loaded data from: https://autogluon-text.s3-accelerate.amazonaws.com/glue/sts/train.parquet | Columns = 4 / 4 | Rows = 5749 -> 5749
Loaded data from: https://autogluon-text.s3-accelerate.amazonaws.com/glue/sts/dev.parquet | Columns = 4 / 4 | Rows = 1500 -> 1500
| 句子1 | 句子2 | 分数 | |
|---|---|---|---|
| 0 | 一架飞机正在起飞。 | 一架飞机正在起飞。 | 5.00 |
| 1 | 一个男人正在吹一个大长笛。 | 一个男人正在吹长笛。 | 3.80 |
| 2 | 一个男人正在把切碎的奶酪撒在披萨上。 | 一个男人正在把切碎的奶酪撒在一个未烹饪的... | 3.80 |
| 3 | 三个男人正在下棋。 | 两个男人正在下棋。 | 2.60 |
| 4 | 一个男人正在拉大提琴。 | 一个坐着的男人正在拉大提琴。 | 4.25 |
| 5 | 一些男人正在打架。 | 两个男人正在打架。 | 4.25 |
| 6 | 一个男人正在抽烟。 | 一个男人正在滑冰。 | 0.50 |
| 7 | 这个男人正在弹钢琴。 | 这个男人正在弹吉他。 | 1.60 |
| 8 | 一个男人正在弹吉他并唱歌。 | 一个女人正在弹原声吉他并唱歌... | 2.20 |
| 9 | 一个人正把一只猫扔到天花板上。 | 一个人把一只猫扔到天花板上。 | 5.00 |
在此数据中,名为 score 的列包含数值(我们希望预测),这些数值是人工为每对给定句子标注的相似度分数。
print('Min score=', min(sts_train_data['score']), ', Max score=', max(sts_train_data['score']))
Min score= 0.0 , Max score= 5.0
让我们训练一个回归模型来预测这些分数。请注意,我们只需要指定标签列,AutoGluon 就会自动确定预测问题的类型和合适的损失函数。再次提醒,您应该增加下面短暂的 time_limit,以便在您自己的应用中获得合理的性能。
sts_model_path = f"./tmp/{uuid.uuid4().hex}-automm_sts"
predictor_sts = MultiModalPredictor(label='score', path=sts_model_path)
predictor_sts.fit(sts_train_data, time_limit=60)
=================== System Info ===================
AutoGluon Version: 1.3.1b20250508
Python Version: 3.11.9
Operating System: Linux
Platform Machine: x86_64
Platform Version: #1 SMP Wed Mar 12 14:53:59 UTC 2025
CPU Count: 8
Pytorch Version: 2.6.0+cu124
CUDA Version: 12.4
Memory Avail: 25.22 GB / 30.95 GB (81.5%)
Disk Space Avail: 183.63 GB / 255.99 GB (71.7%)
===================================================
AutoGluon infers your prediction problem is: 'regression' (because dtype of label-column == float and label-values can't be converted to int).
Label info (max, min, mean, stddev): (5.0, 0.0, 2.701, 1.4644)
If 'regression' is not the correct problem_type, please manually specify the problem_type parameter during Predictor init (You may specify problem_type as one of: ['binary', 'multiclass', 'regression', 'quantile'])
AutoMM starts to create your model. ✨✨✨
To track the learning progress, you can open a terminal and launch Tensorboard:
```shell
# Assume you have installed tensorboard
tensorboard --logdir /home/ci/autogluon/docs/tutorials/multimodal/text_prediction/tmp/eaeecaabc96848eeaa2e16ba745e2d06-automm_sts
```
Seed set to 0
GPU Count: 1
GPU Count to be Used: 1
Using 16bit Automatic Mixed Precision (AMP)
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
HPU available: False, using: 0 HPUs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params | Mode
---------------------------------------------------------------------------
0 | model | HFAutoModelForTextPrediction | 108 M | train
1 | validation_metric | MeanSquaredError | 0 | train
2 | loss_func | MSELoss | 0 | train
---------------------------------------------------------------------------
108 M Trainable params
0 Non-trainable params
108 M Total params
435.570 Total estimated model params size (MB)
229 Modules in train mode
0 Modules in eval mode
Epoch 0, global step 20: 'val_rmse' reached 0.65092 (best 0.65092), saving model to '/home/ci/autogluon/docs/tutorials/multimodal/text_prediction/tmp/eaeecaabc96848eeaa2e16ba745e2d06-automm_sts/epoch=0-step=20.ckpt' as top 3
Epoch 0, global step 40: 'val_rmse' reached 0.53887 (best 0.53887), saving model to '/home/ci/autogluon/docs/tutorials/multimodal/text_prediction/tmp/eaeecaabc96848eeaa2e16ba745e2d06-automm_sts/epoch=0-step=40.ckpt' as top 3
Epoch 1, global step 61: 'val_rmse' reached 0.49104 (best 0.49104), saving model to '/home/ci/autogluon/docs/tutorials/multimodal/text_prediction/tmp/eaeecaabc96848eeaa2e16ba745e2d06-automm_sts/epoch=1-step=61.ckpt' as top 3
Time limit reached. Elapsed time is 0:01:07. Signaling Trainer to stop.
Start to fuse 3 checkpoints via the greedy soup algorithm.
Using default `ModelCheckpoint`. Consider installing `litmodels` package to enable `LitModelCheckpoint` for automatic upload to the Lightning model registry.
Using default `ModelCheckpoint`. Consider installing `litmodels` package to enable `LitModelCheckpoint` for automatic upload to the Lightning model registry.
Using default `ModelCheckpoint`. Consider installing `litmodels` package to enable `LitModelCheckpoint` for automatic upload to the Lightning model registry.
AutoMM has created your model. 🎉🎉🎉
To load the model, use the code below:
```python
from autogluon.multimodal import MultiModalPredictor
predictor = MultiModalPredictor.load("/home/ci/autogluon/docs/tutorials/multimodal/text_prediction/tmp/eaeecaabc96848eeaa2e16ba745e2d06-automm_sts")
```
If you are not satisfied with the model, try to increase the training time,
adjust the hyperparameters (https://autogluon.cn/stable/tutorials/multimodal/advanced_topics/customization.html),
or post issues on GitHub (https://github.com/autogluon/autogluon/issues).
<autogluon.multimodal.predictor.MultiModalPredictor at 0x7f439c885850>
我们再次在单独的测试数据上评估我们训练好的模型的性能。下面我们选择计算以下评估指标:RMSE、Pearson 相关系数和 Spearman 相关系数。
test_score = predictor_sts.evaluate(sts_test_data, metrics=['rmse', 'pearsonr', 'spearmanr'])
print('RMSE = {:.2f}'.format(test_score['rmse']))
print('PEARSONR = {:.4f}'.format(test_score['pearsonr']))
print('SPEARMANR = {:.4f}'.format(test_score['spearmanr']))
RMSE = 0.93
PEARSONR = 0.8032
SPEARMANR = 0.8029
Using default `ModelCheckpoint`. Consider installing `litmodels` package to enable `LitModelCheckpoint` for automatic upload to the Lightning model registry.
让我们使用我们的模型来预测几个句子之间的相似度分数。
sentences = ['The child is riding a horse.',
'The young boy is riding a horse.',
'The young man is riding a horse.',
'The young man is riding a bicycle.']
score1 = predictor_sts.predict({'sentence1': [sentences[0]],
'sentence2': [sentences[1]]}, as_pandas=False)
score2 = predictor_sts.predict({'sentence1': [sentences[0]],
'sentence2': [sentences[2]]}, as_pandas=False)
score3 = predictor_sts.predict({'sentence1': [sentences[0]],
'sentence2': [sentences[3]]}, as_pandas=False)
print(score1, score2, score3)
4.3645306 3.5593908 1.3538214
Using default `ModelCheckpoint`. Consider installing `litmodels` package to enable `LitModelCheckpoint` for automatic upload to the Lightning model registry.
Using default `ModelCheckpoint`. Consider installing `litmodels` package to enable `LitModelCheckpoint` for automatic upload to the Lightning model registry.
Using default `ModelCheckpoint`. Consider installing `litmodels` package to enable `LitModelCheckpoint` for automatic upload to the Lightning model registry.
尽管 MultiModalPredictor 当前支持分类和回归任务,但如果您将其正确格式化为数据表,则可以直接用于许多 NLP 任务。请注意,此数据表中可以有许多文本列。请参考 MultiModalPredictor 文档以查看所有可用方法/选项。
与训练/集成不同类型模型的 TabularPredictor 不同,MultiModalPredictor 专注于选择和微调基于深度学习的模型。在内部,它集成了 timm、huggingface/transformers、openai/clip 作为模型库。
其他示例¶
您可以访问 AutoMM 示例来探索其他 AutoMM 示例。
自定义¶
要了解如何自定义 AutoMM,请参考 自定义 AutoMM。